本次分享主题是多任务学习在风控场景中的应用探索,主要探讨什么是样本选择偏差问题,如何从多任务学习的角度解决样本选择偏差问题,什么是多任务学习,多任务学习有哪些优点以及常见的解决思路。还会分享本团队在捞回和文本两个场景上的应用案例,并详细介绍我们结合风控场景的特点如何定制化多任务学习方法解决样本偏差的问题。今天的介绍会按照以下顺序展开:
- 风控场景中的问题
- 多任务学习概况
- 应用案例
- 时序多任务学习方法
01 风控场景中的问题
1. 风控算法的瓶颈
影响风控模型效果的主要因素包括:样本、标签、特征和算法。长期以来,业务模型主要关注前三个因素:
- 如何选择客群样本使模型更加稳定
- 根据业务逾期率要求设计标签开发首期、三期模型
- 对数据进行特征工程,引入第三方数据等
算法上XGBoost、LightGBM等主流树模型是模型效果的标杆,深度模型往往难以超越树模型。近几年风控算法通过GNN图神经网络取得了一些突破,但在落地上还存在一些问题。面对这么多瓶颈,风控模型在算法上没有提升空间了吗?如果把风控模型局限在基于数值型结构化数据的分类任务上,可能确实难以提升了,但转化一下思路,能否针对性的对风控场景存在的问题设计对应的解决方法来提高模型效果呢?答案在下文中揭晓。
2. 样本选择偏差
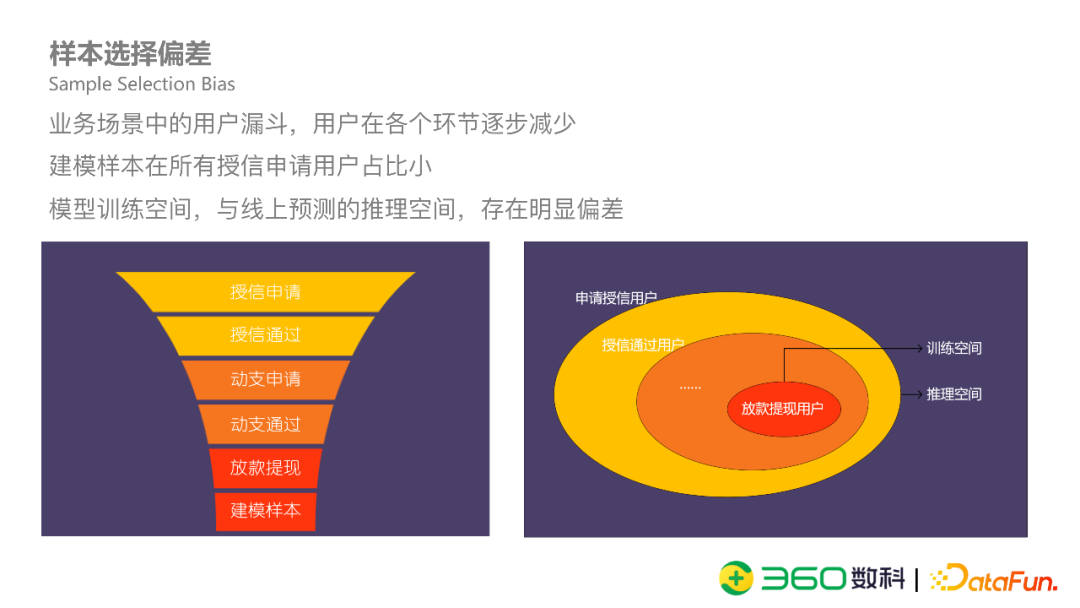
我们瞄准的问题是样本选择偏差。
在金融信贷中,用户要先申请,再动支,最终有逾期表现,整个过程中,用户逐步减少。一般来说,大部分用户的申请都会被拒绝,通过的用户有一小部分没有发起动支,最终有逾期行为的用户就更少了。常规建模方法只能用这很小一部分用户去训练模型,而模型在线上使用的时候,则是面对所有申请用户。这样造成了模型训练空间与线上预测推理空间有明显偏差。
3. 样本选择偏差的影响

模型拟合的是局部,本身便存在偏差,客群发生变化时,模型效果可能会发生衰减。
举一个简单的例子:如上图所示,左边是有偏样本得到的模型,分类超平面将好人和坏人分开,左边绿色是好人,右边红色是坏人,此时只有一个红色样本被分错了。但放到右边全样本空间看,超平面左边有大量的红点被认为是好人,分类误差很大,而更好的模型可能是右边新增的超平面。在现实情况中,常规用的树模型是一个非线性模型,是对空间更复杂的划分,相对没有示意图这么极端,误差相对较小。
样本偏差在迭代过程中会不断累积。有偏样本导致模型本身有偏,用有偏模型去筛选用户,下次用这些用户再次建模,导致偏差不断累积,最终通过的用户越来越偏。

样本选择偏差还可能会导致建模样本量太少,尤其是在某些新产品的冷启动阶段。我们以上图中某一个风控产品为例(数据经过脱敏处理),申请用户大概70多万,经过授信审批和动支两个阶段后,最终有逾期表现的只有8万多,在这个量级下还要分训练集、验证集、OOT等就很难得到稳定有效的模型。
4. 解决样本偏差的方法
传统解决样本选择偏差的方法是拒绝推断。例如硬截断法、模糊展开法、双评分卡法、self-training自训练等,总结来说是通过不同方法得到拒绝样本的逾期标签,总体提升较为有限。本身这是一个无中生有的方法,用这些本来就没有逾期标签的样本训练,不管什么方法得到的标签误差都是比较大的。
有没有方法不需要得到用户的逾期标签,就能解决样本选择偏差问题?我们想到了从多任务学习的视角去解决。拒绝用户虽然没有逾期标签,但有通过和拒绝标签,有动支标签,这些标签本身和风险是强相关的。如果利用这些标签和逾期标签一起训练,则构成了多任务学习。且这些标签覆盖更全,偏差更小,用来辅助逾期模型的训练,可以有效缓解样本选择偏差的问题。
02 多任务学习概况
1. 多任务学习定义


多任务学习,简单来说是把多个相关任务放在一起学习,通过相互分享、补充领域相关知识,提高泛化效果。可以将多任务学习理解为知识迁移:单任务学习时,两个任务独立学习各自的模型参数;多任务模型之间会有部分参数共享,用来学习任务之间的公共部分,部分参数不共享,用来学习任务之间有差异的部分。图中右侧的多任务学习网络参数共享方法是硬共享,所有任务直接共享公共部分。
2. 多任务学习优势
多任务学习优势在于一个模型可以解决多个任务,比如首期、三期、六期等风险预测建模都可以通过一个模型解决。此外,利用任务之间的差异可以增加泛化能力,防止过拟合于某个单一的任务。通过多任务模型还可以进行知识迁移,提高主任务的效果。多任务学习可以解决冷启动问题与主任务训练困难的问题,如之前所说主任务样本少,有相关样本量足够的辅助任务,就可以解决主任务训练困难的问题。
3. 多任务学习的常规方法

多任务学习的优化有几种,第一种是对共享层改进的MoE和MMoE方法。
相对前文所说的硬共享方法,图中方法称为软共享,是指底层参数并非直接全部共享,而是增加了Expert和Gate两个模块,一般称为专家模块和门控结构。专家模块是任务之间是共享的,但每个专家学习到的知识是有差异的,可以理解为每一个专家模块学习到的是各自领域内的知识,通过门控结构对多个专家意见加权求和,得到综合意见。门控结构可以理解为对专家模块的信息过滤,假如Expert 0的权重大,则说明对这个专家意见保留较多。MoE和MMoE这两种方法区别在于MoE是多个任务共享一个gate,而MMoE是每个任务都有自己的gate,思路上都是对共享层的控制。门控结构是通过注意力机制来训练。

第二种优化思路是对输出层做改进,典型方法是ESMM。ESMM是阿里针对转化率预估问题提出的,主要为了解决广告推荐场景里样本选择偏差问题。简单介绍一下转化率预估问题:商品在展示后,用户可能会发生点击行为,在点击之后,用户可能会发生购买(转化)行为。转化是在点击后发生的,广告的点击率一般较低,预估模型的样本偏差是非常严重的。ESMM方法巧妙地把转化预估转为点击且转化预估。用户的点击是无偏的,但转化是有偏的,引入点击且转化任务建模为点击率*转化率,通过训练点击和点击且转化任务,间接训练转化率预估任务,也就解决了转化率预估的样本偏差问题。最终带入到损失函数中的是点击和点击且转化这两个任务,转化率预估任务不直接放在损失函数里边。
除了MMoE和ESMM两个思路,还有一些多任务学习方法是对目标函数进行改进,不同任务在一起训练任务分布、重要性、难度等都也不一样,对loss直接相加是不合适的。人工trick,可以主任务给大权重,辅助任务给小权重;难任务给大权重,简单任务小权重等。此外还有一些自适应动态调整权重的方法或者是给目标函数加约束的方法,这里就不多做介绍了。
03 应用案例
1. 多任务捞回模型

捞回模型是指在主模型拒绝的用户上捞回部分用户。
我们在常规实验中发现,无论是用捞回用户建模,还是主用户和捞回用户一起建模,实际模型都不太稳定。我们思考原因,做了一个形象但不太严谨的描述:主模型就像图中的蓝色的圆,捞回模型是在此之外去寻找低风险的人,而外面空间太大了,没有明确的方向性,能否利用主模型给捞回模型增加一些方向约束,使捞回模型大部分继承主模型对于风险的判断,同时扩散式的向外召回?

我们用多任务的思路设计了通过标签和风险标签这两个标签,通过标签建模主模型的通过和拒绝,风险标签建模用户逾期表现。
我们用XGBoost模型的叶子节点作为特征,通过神经网络训练多任务模型,可以类比为XGBoost加LR的结构。
这种做法主要考虑神经网络对于数值型的特征拟合并不好,通过xgb预训练方式增强对风险标签的拟合。中间是两个任务共享的全连接神经网络用来训练多任务。这不是端对端的模型,是初期对做任务的一个探索,但最终取得的效果还是很不错的。右边是多任务捞回模型的线上效果图,在上线一年时间里,常规模型效果衰减比较严重,多任务模型效果比较稳定。
2. transformer多任务模型

我们第二个应用案例是基于文本数据的多任务模型。
此文本数据是一个非结构化的数据,定义了十个标签,包含通过拒绝、借款间隔等。通过多任务学习可以对不同的任务目标进行组合,实现信息互补。具体实现是通过图中的Transformer网络,其中Encoder部分信息是共享的,Classifer部分是独立的,相当于前问中的tower部分。最终经过实验验证,该Transformer分类模型能够使这些标签上Auc能提高2个点左右。
04 时序多任务学习方法
1. 多任务场景分析

接下来所讲的是我们结合业务设计了什么方法去解决样本选择偏差问题。
首先风控业务中的场景分析包含申、请动支、风险表现三个阶段。这三个阶段是根据时间上的先后顺序对场景做了一下简化,事实在用户动支之后还有动支审批、资方审批等阶段。申请阶段只有一个标签,即通过或拒绝;动支阶段可能有多个标签,根据用户动支时间和申请时间的间隔分为短间隔、中间隔、长间隔等。风险阶段也有多个标签,短期风险中期风险或者是长期风险。
有几个关键问题是:风控建模预测的是风险,风险是主要任务,其他的通过、拒绝和动支作为辅助任务,但一般的多任务学习方法是没有时序关系的,如何设计一种网络结构可以有效利用任务之间的时序关系是个关键点。
2. 网络结构

如图所示,网络结构从下往上分别是共享层,申请、动支、风险三个构成的时序tower层,最后是输出层。与传统的多任务学习一样,共享层参数共享,tower层参数不共享。不同的是我们创新性的提出了info信息桥部分,用于建模阶段间的顺序依赖并进行信息传递。
3. 分层注意力

Info信息桥通过分层注意力实现,分层注意力分为两步,第一步是阶段内注意力,将动支间隔等内部任务标签学到的表示向量进行聚合;第二步是阶段间注意力,是对聚合之后的信息做过滤,在任务之间对有用信息进行有向传递,丢弃无用信息。
4. 半监督损失函数

我们引入交叉熵正则损失函数进行半监督学习。
交叉熵正则是一种简单有效的半监督学习方式。目标函数中有标签的用户会计算交叉熵损失函数,没有标签的用户计算交叉熵正则。最终的损失函数是三个阶段的损失函数通过不同的权重求和。
5. 实验效果

与主流的方法对比,本文提出的时序多任务风控建模方法MSIS的Auc增益在2%左右。

同时我们通过消融实验证明了每个网络中每个部分都是有效的。

最后我们做了参数敏感性实验,在不同的参数下,本文提出的方法是较为稳定有效的。
05 总结
总结来说,本文主要提出了几种方法解决风控场景中的样本偏差问题。
一是以样本偏差小的任务辅助逾期任务训练;二是通过设计网络结构,实现多阶段多标签任务的共同训练;三是设计信息连廊,通过分层注意力机制,实现信息聚合和有效传递。
06 Q&A
Q:用全部申请样本在后标签好坏定义时,没有动支样本的target是如何定义的?
A:没有动支或者通过的样本在风险阶段是没有好坏标签的,本方法中也不需要给出好坏标签。申请阶段中的标签是通过或者拒绝,用全量样本训练;在动支阶段则只用通过样本训练,动支标签是近多少天内是否动支;申请通过且动支的用户才会进入风险阶段,产生逾期表现,有好坏标签。没有标签的用户采用交叉熵正则作为补充算损失函数。
Q:在申请阶段,用本文提出的神经网络方法怎么去解释模型?
A:LR和XGB树模型等相对比较好解释,神经网络模型只能借助外部工具进行解释。
Q:本文提出的模型和AITM模型的区别?
A:不同点有两个地方:一是AITM的方法只是前后任务直接传递,每个阶段只有一个标签,而本文的方法的不同阶段可以有多个标签,引入多个标签可以更好地辅助风险任务的训练。二是交叉熵正则的损失函数有所区别。
Q:不同任务损失函数融合权重如何设计?
A:可以根据任务主次,比如主任务是逾期任务,其任务权重可以尝试设大一些,辅助任务权重设小一些。第二个是根据任务难易,难任务可以设置大一些,比如申请动支的标签易训练,后两个任务难训练一些,可以把第一个阶段权重设小一些,后面任务权重设大一些。
Q:能否详细介绍一下交叉熵正则损失?
A:最终的损失函数是多个阶段损失函数的加权融合,对每个阶段损失函数展开,包括两个部分——有标签和无标签。有标签部分的损失采用交叉熵损失,无标签部分是交叉熵正则损失。交叉熵损失计算公式中的P是真实标签,而交叉熵正则的P是模型预测的打分。最终训练的结果是让模型对无标签样本的打分稳定下来。
Q:在申请、动支、风险三个任务效果都有变好吗?是否会有跷跷板效应?
A:跷跷板效应是指多任务学习中,某一任务效果变好了,有其他任务效果下降了。我们的主要任务是提高风险阶段的AUC,风险阶段的AUC较高,申请和动支的AUC稍弱一点我们是可以接受的。
今天的分享就到这里,谢谢大家。