
🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.项目简介
2.1项目说明
2.2数据说明
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2数据预处理
4.3探索性数据分析
4.3.1.分析满意度与离职的关系
4.3.2分析考核得分与离职的关系
4.3.3分析工程数量与离职的关系
4.3.4分析月工时与离职的关系
4.3.5分析工龄与离职的关系
4.4特征工程
4.5模型构建
4.6参数调优
4.7模型评估
4.8模型预测
5.实验总结
1.项目背景
对企业而言,适当的人员流动以及新老员工的交替,可以给企业带来新的生命力与鲜适的生机。但是,过高的员工流失率,就会影响到企业的稳定性和健康发展。因为员工流动频繁,新员工重新熟悉工作岗位和企业环境,需要一定的适应周期,如此势必会浪费一定的时间成本和人力成本;同时,还可能会导致产品质量和生产效率的较大波动。我们通常将一般的企业的年离职率设置在8%为目标,而实际上许多的企业的员工流失率大都远远超出这个范围。富士康科技集团被誉为全球最大的代工工厂,中国内地有超过100万的工人,占总人力的85%以上。以富士康ccpbg-mit事业处烟台厂区为例,近5年的员工离职率平均在21.3%左右,其中离职员工主要为一线员工,入职时间不满一年。类似的事情在德尔福同样发生过。可见,制造企业,面临的流水线员工高频率流动、流失率居高不下的问题已十分严峻。我们为了解决问题,将分析企业员工离职原因,并且提出一些建议。
2.项目简介
2.1项目说明
本项目旨在分析该公司员工是离职数据,得出员工离职的原因,提出建议,最后构建员工离职模型,时刻关注员工情况,实现精准预测,及时做出调整,避免人员流失。
2.2数据说明
数据集来源于kaggle平台,是一家公司员工离职数据集,共有15000行,7列。具体字段信息如下:
| 属性名 | 属性描述 |
| 工资 | 薪资等级(低、中、高),object字符类型 |
| 满意度 | 员工对工作的满意度,float浮点类型 |
| 考核得分 | 员工的工作考核得分,float浮点类型 |
| 工程数量 | 员工的总工程项目数量,int整数类型 |
| 月工时 | 员工的月工作小时,int整数类型 |
| 工龄 | 员工的工龄,int整数类型 |
| 离职 | 员工是否离职(否0,是1),int整数类型 |
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
决策树( Decision Tree) 又称为判定树,是数据挖掘技术中的一种重要的分类与回归方法,它是一种以树结构(包括二叉树和多叉树)形式来表达的预测分析模型。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。一般,一棵决策树包含一个根节点,若干个内部结点和若干个叶结点。叶结点对应于决策结果,其他每个结点对应于一个属性测试。每个结点包含的样本集合根据属性测试的结果划分到子结点中,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定的测试序列。决策树学习的目的是产生一棵泛化能力强,即处理未见示例强的决策树。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
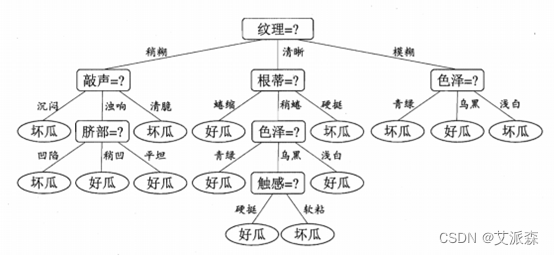
决策树的构建
特征选择:选取有较强分类能力的特征。
决策树生成:典型的算法有 ID3 和 C4.5, 它们生成决策树过程相似, ID3 是采用信息增益作为特征选择度量, 而 C4.5 采用信息增益比率。
决策树剪枝:剪枝原因是决策树生成算法生成的树对训练数据的预测很准确, 但是对于未知数据分类很差, 这就产生了过拟合的现象。涉及算法有CART算法。
决策树的划分选择
熵:物理意义是体系混乱程度的度量。
信息熵:表示事物不确定性的度量标准,可以根据数学中的概率计算,出现的概率就大,出现的机会就多,不确定性就小(信息熵小)。
4.项目实施步骤
4.1理解数据
首先导入员工离职数据集
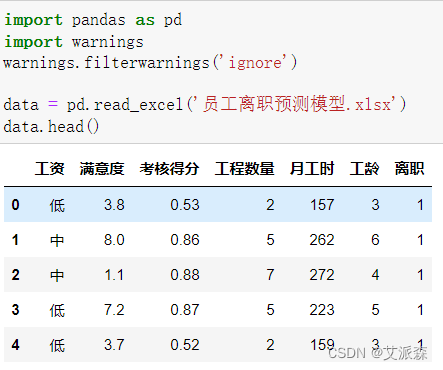
查看数据大小

原始数据集共有15000行,7列
查看数据基本信息
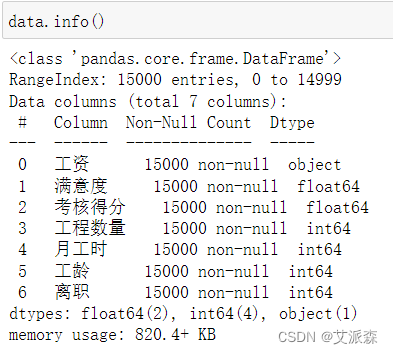
从结果中看出,原始数据集中不存在缺失值,故不需要进行缺失值处理
查看数据描述性信息
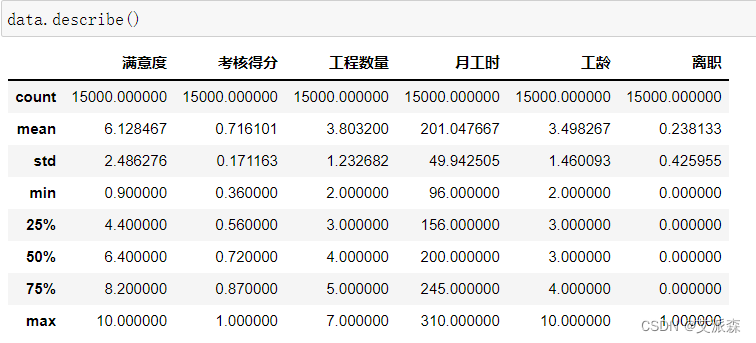
从结果中可看出各特征的均值、方差、最大最小和四分位数等信息
4.2数据预处理
前面我们发现数据集不存在缺失值,所以这里我们对重复值进行删除
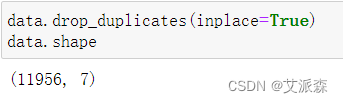
从结果中看出,重复的数据共有3044个
4.3探索性数据分析
4.3.1.分析满意度与离职的关系
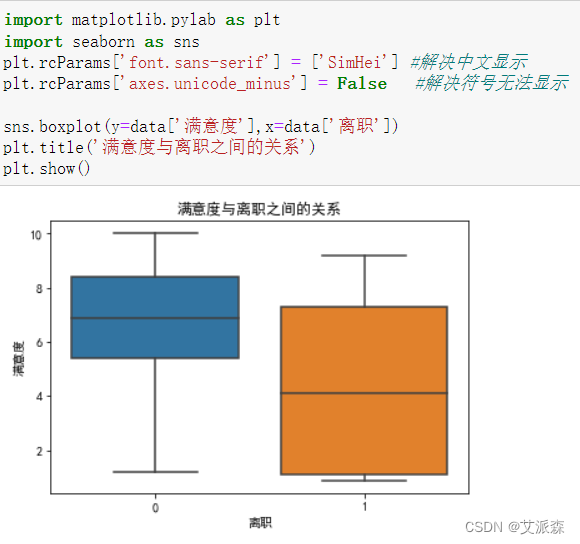
通过箱型图我们发现,离职的员工对于工作的满意度显著低于在职员工的满意度,说明满意度是员工离职的一个重要因素,企业应当重视,增加员工的满意度,从双因素理论来说,企业在保证满足员工的保健因素外,还应当重视员工的激励因素。
4.3.2分析考核得分与离职的关系
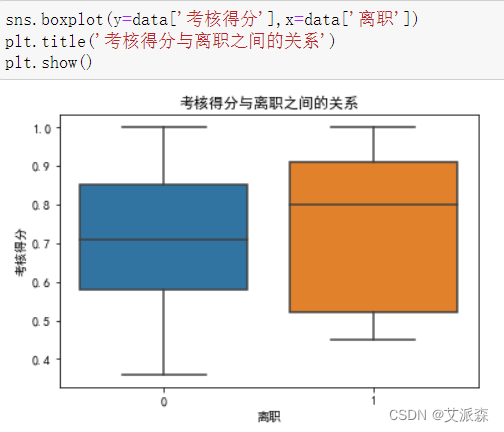
通过箱型图发现,考核得分与离职之间的关系不是很明显,但是离职员工的最低考核得分比在职员工高且中位数也比在职员工高,说明离职的员工大部分还都是比较优秀的员工,这样的话企业更应该重视员工的离职情况,避免人才流失。
4.3.3分析工程数量与离职的关系
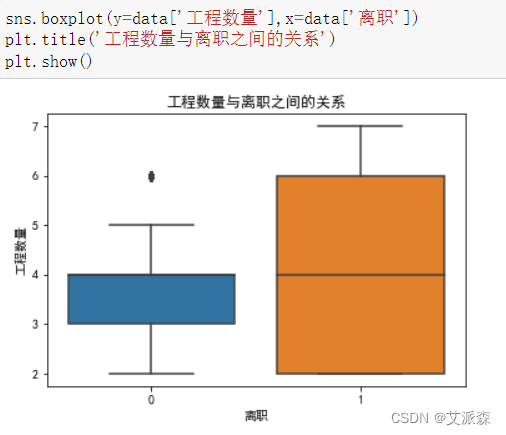
通过箱型图发现,离职员工的工程数量明显多于在职员工,说明员工离职的原因可能是因为工程数量太多,导致工作繁忙,压力大。作为企业,应该适当安排工作量,避免出现一个员工的工程数量过大。
4.3.4分析月工时与离职的关系
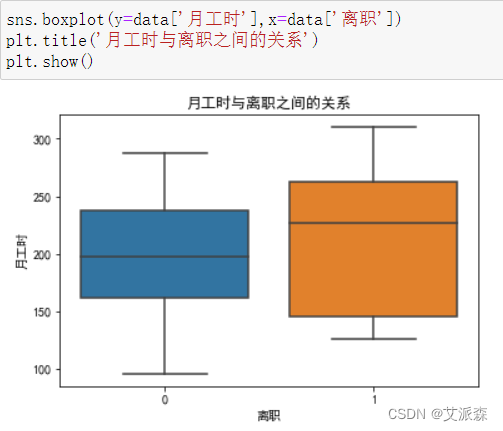
通过箱型图发现,离职员工的月工时也是明显大于在职员工的,也间接证明了前面说的工程数量,所以这是同样的问题导致,企业应当采取相应的策略来解决这一问题。
4.3.5分析工龄与离职的关系
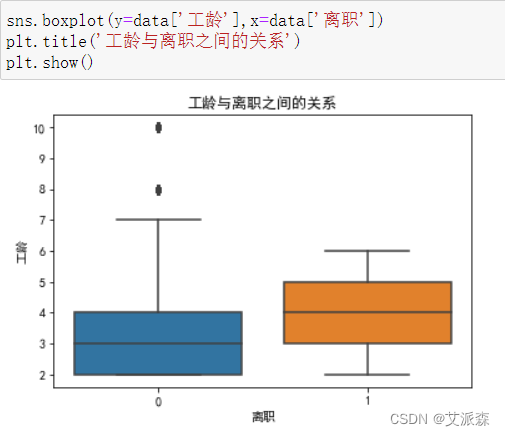
从图发现,离职员工的工龄一般为3-5年,一般来说工龄越大离职的可能性越大,所有该企业应当在员工的工龄在3-5年的时候,多关注一下员工的满意度情况,采取一些策略,经最大可能减少人员流失。
4.3.6分析薪资与离职的关系
- low_salary_dimission_rate = data[data['工资']=='低']['离职'].value_counts().values.tolist()[1]/sum(data[data['工资']=='低']['离职'].value_counts().values.tolist())
- mid_salary_dimission_rate = data[data['工资']=='中']['离职'].value_counts().values.tolist()[1]/sum(data[data['工资']=='中']['离职'].value_counts().values.tolist())
- high_salary_dimission_rate = data[data['工资']=='高']['离职'].value_counts().values.tolist()[1]/sum(data[data['工资']=='高']['离职'].value_counts().values.tolist())
- dimission_rate = pd.DataFrame()
- dimission_rate = pd.DataFrame(columns=['离职率'],index=['低','中','高'],data=[low_salary_dimission_rate,mid_salary_dimission_rate,high_salary_dimission_rate])
- dimission_rate.plot(kind='barh')
- plt.title('薪资等级与离职率之间的关系')
- plt.show()
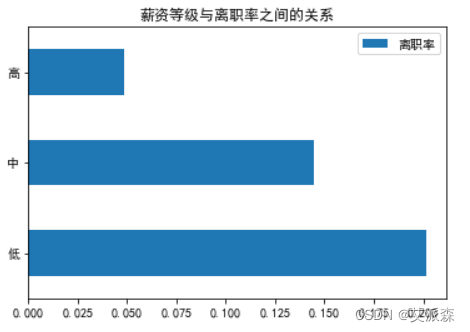
从图中看出,薪资等级越低,员工的离职率越高,薪资低的离职率为20%,数字还是比较大的,企业应该给员工加薪或者多加一些福利政策,以此来留住人才。
最后我们看下原始数据集中离职和在职数据的比例情况
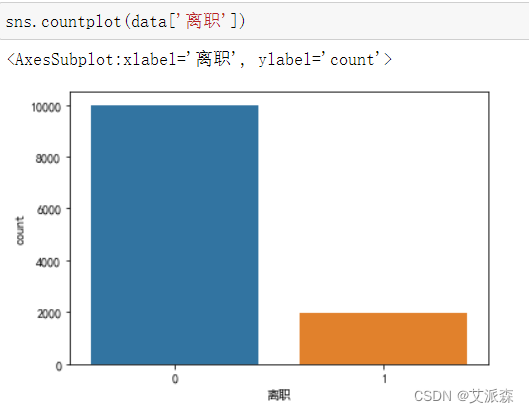
从图看出,离职的数据远远小于在职数据,数据不均衡,所以在建模之前需要进行欠采样处理。
4.4特征工程
首先对工资等级进行编码处理,将字符型数据转化为数值型

接着对数据进行欠采样处理,这里用到的第三方库imblearn需要进行安装(pip install imblearn)

4.5模型构建
在模型构建之前,我们先对数据集进行拆分为训练集和测试集,测试集比例为0.2
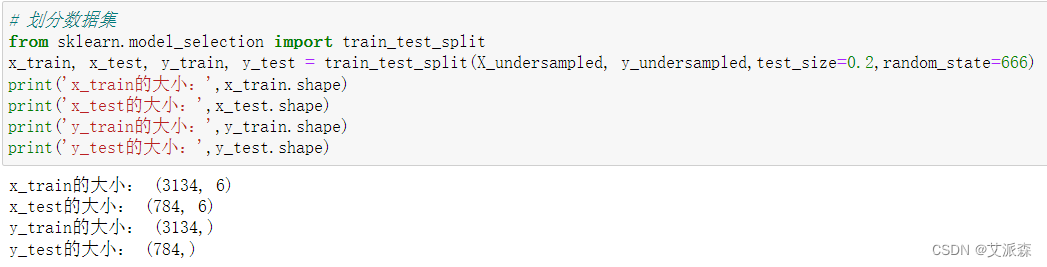
构建决策树模型并输出其模型准确率
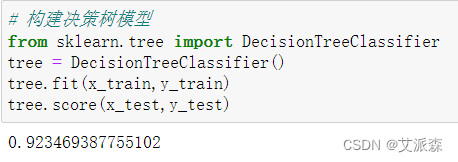
可以看出决策树模型准确率为0.92,较为不错。
4.6参数调优
这里我们使用网格搜索进行参数调优选择
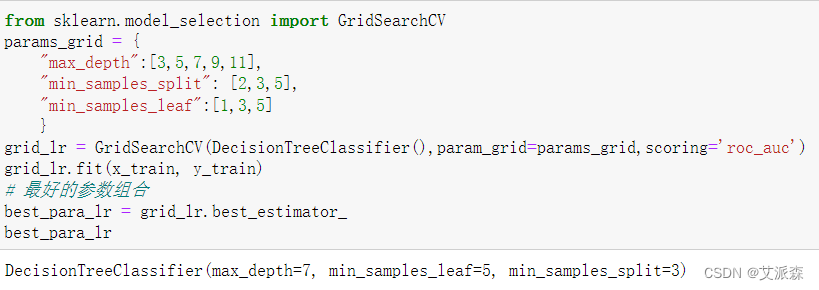
接着使用最优模型参数组合重新训练模型

从结果看出优化后的模型准确率为0.95,相较于前面的0.93,模型准确率提高了不少。
4.7模型评估
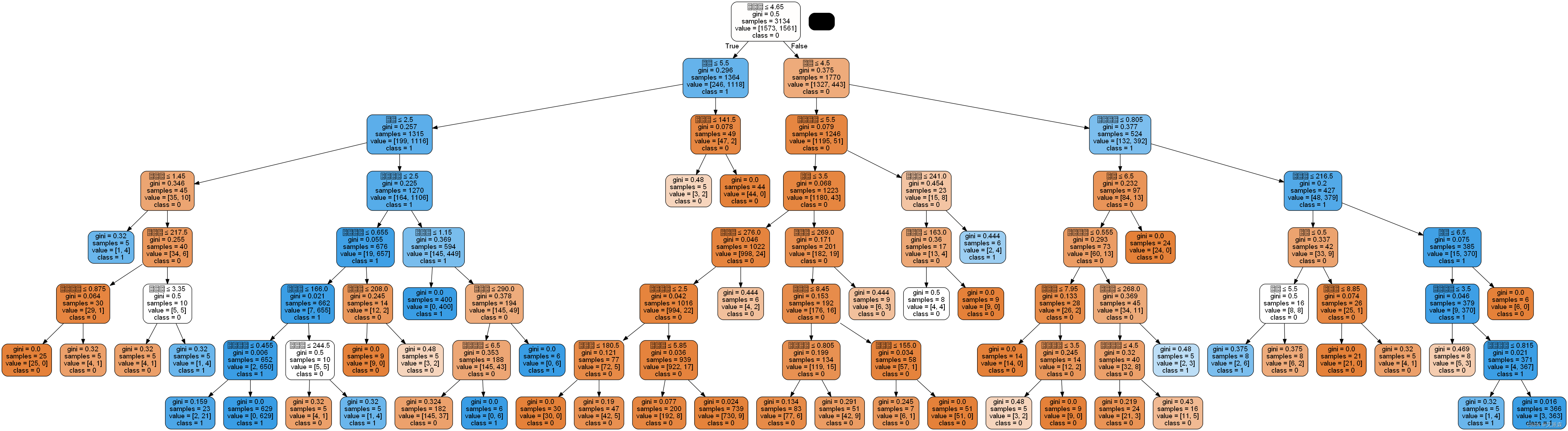
首先先将最优模型的决策树可视化
接着查看模型的分类报告、混淆矩阵和ROC曲线
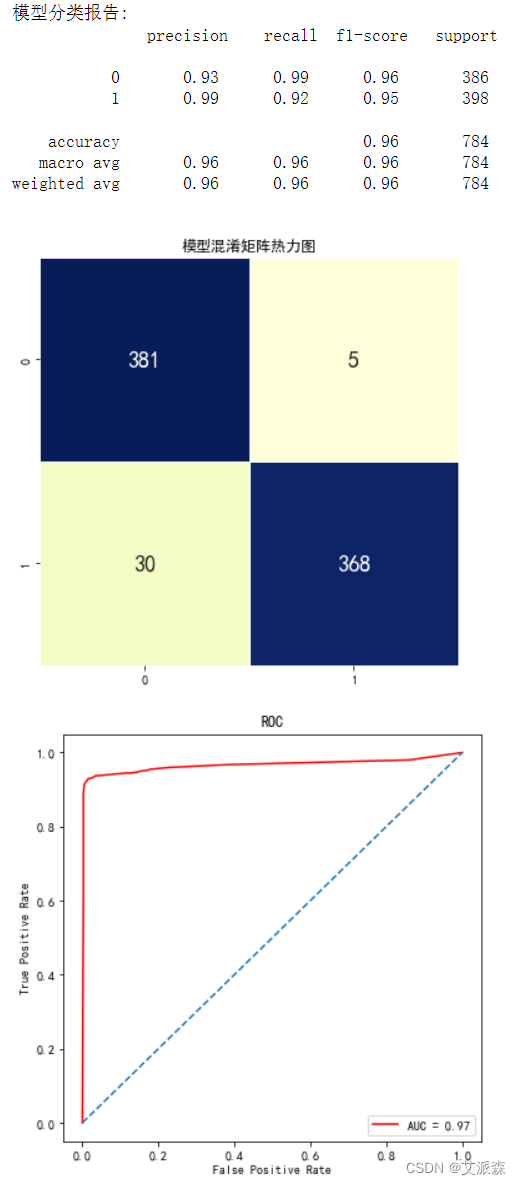
模型分类报告中可以看出模型在0和1分类上的精确率、召回率和F1值等信息。在模型混淆矩阵中可以看出模型在预测0和1分类时,预测正确和错误的个数。最后从ROC曲线可看出曲线靠近左上角,模型效果不错,且AUC值为0.97。
4.8模型预测
这里我们使用测试集中的前十条数据来进行模型预测
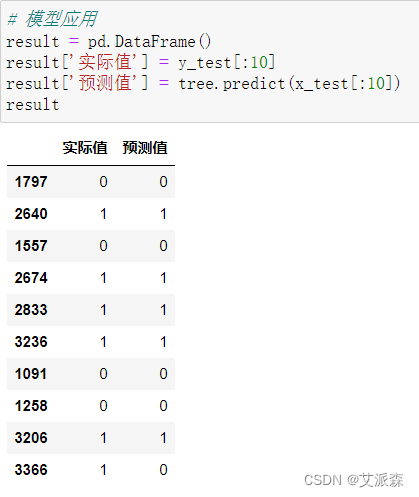
从结果中看出,模型预测正确了9个错误了1个。
5.实验总结
本次实验通过分析企业员工离职数据,得出影响员工离职因素较大的是满意度、工程数量、月工时和薪资。企业应该在这些方面进行改进优化,比如给员工增加薪资或福利,给员工下发的任务数量要合理等等来提高员工的满意度,减少人员流失。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。


