
本文长期不定时更新最新知识,防止迷路记得收藏哦!
还未了解基础GAN的,可以先看下面两篇文章:
GNA笔记--GAN生成式对抗网络原理以及数学表达式解剖
入门GAN实战---生成MNIST手写数据集代码实现pytorch
背景介绍
2016年,Alec等人发表的论文《UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS》(简称DCGAN),首次提出将卷积神经网络应用到GAN生成对抗网络的模型中,从而代替全连接层。这篇论文中讨论了GAN特征的可视化、潜在空间差值等。本文知识总结来源也是这篇论文。
从大型未标记数据集中学习可重用的特征表示一直是一个活跃的研究领域。在计算机视觉环境中,人们可以利用几乎无限量的未标记图像和视频来学习良好的中间表示,然后可以将其用于各种有监督的学习任务,如图像分类。建立良好图像表示的一种方法是训练生成性对抗网(GANs),然后将生成器和鉴别器网络的一部分重新用作监督任务的特征提取器。GANs为最大似然法提供了一种有吸引力的替代方法。此外,人们可以认为,他们的学习过程和缺乏启发式成本函数(如像素独立均方误差)对表征学习很有吸引力。众所周知,GANs的训练不稳定,常常导致发电机产生无意义的输出。在试图理解和可视化GANs学习的内容以及多层GANs的中间表示方面,已经发表的研究非常有限。
一、什么是DCGAN?
DCGAN是GAN的一个变体,DCGAN就是将CNN和原始的GAN结合到一起,生成网络和鉴别网络都运用到了深度卷积神经网络。DCGAN提高了基础GAN的稳定性和生成结果质量。
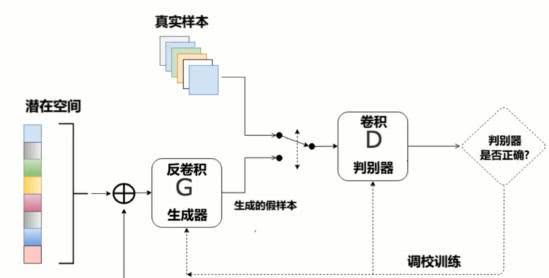
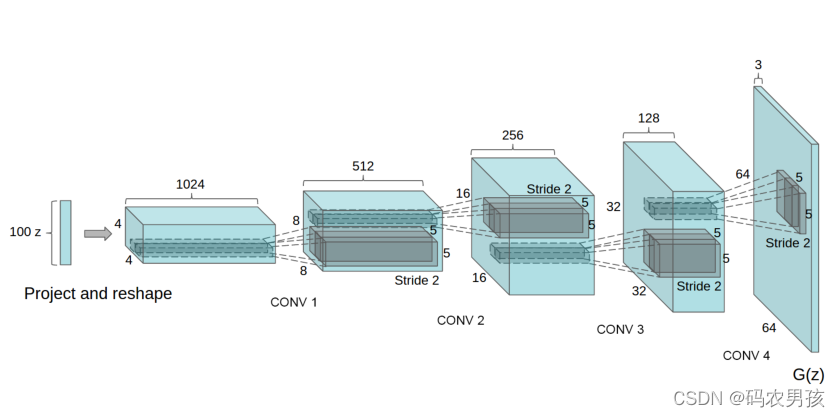
二、与基础GAN相比,改进方面?
DCGAN主要是在网络架构上改进了原始GAN,DCGAN的生成器和鉴别器都利用CNN架构替换了原始GAN的全连接网络,主要改进之处有如下几个方面:
- DCGAN的生成器和鉴别器都舍弃了CNN的pooling层(池化层),鉴别器保留CNN的整体架构,生成器则是将卷积层替换成了反卷积层(ConvTranspose2d)
- 在鉴别器和生成器中使用了BN(Batch Normalization)层,加速模型训练,提升了训练的稳定性。但是在生成器的输出层和鉴别器的输入层不使用BN层【直接应用batchnorm到所有层会导致样本振荡和模型不稳定】
- 生成器网络中使用ReLU作为激活函数,最后一层使用Tanh()【使用有界激活(a bounded activation)可以让模型更快地学习,以饱和和覆盖训练分布的颜色空间】
- 鉴别器网络中使用LeakyReLU作为激活函数
- 使用Adam优化器,一阶矩估计的指数衰减率的值设置为0.5
三、论文中一些参数推荐
- 所有模型均采用小批量随机梯度下降(SGD)训练,Batch_size大小为128。
- 所有权重均根据零中心正态分布进行初始化,标准偏差为0.02。
- 在LeakyReLU中,斜率均设置为0.2。
- 使用了Adam优化器并调整超参数。基础GAN中建议的学习率0.001太高了,改为使用0.0002。
- 此外,将动量项β1保留在建议值0.9会导致训练振荡和不稳定性,而将其降低到0.5有助于稳定训练。
四、论文中提及到的训练
论文中提到模型在三个数据集上对DCGANs进行了训练,即大规模场景理解(LSUN)、Imagenet-1k和一个新组装的人脸数据集。下面给出了每个数据集的训练细节
1.LSUN
随着生成图像模型样本的视觉质量的提高,对训练样本的过度拟合和记忆的担忧也随之增加。为了观察训练的模型如何随着更多数据和更高分辨率的生成而扩展,在包含300多万个训练示例的LSUN Bedrooms数据集上训练了一个模型。实验证明,模型的学习速度与其泛化性能之间存在直接联系。 【没有对图像进行数据增强】
上图为1个训练时期的样本
 上图为 5个epoch后的结果
上图为 5个epoch后的结果
2.FACES
这个数据集有来自1万人的300万张图片。我们在这些图像上运行OpenCV人脸检测器,使检测保持足够高的分辨率,这为我们提供了大约350000个face boxes,我们用这些face boxes来训练。
3.IMAGENET-1K
使用Imagenet-1k 作为无监督训练的自然图像源,We train on 32 × 32 min-resized center crops
五、对DCGAN能力的证明
评估无监督表示学习算法质量的一种常用技术是将其作为有监督数据集的特征提取器应用,并评估基于这些特征的线性模型的性能。
使用GANS作为特征提取器对CIFAR-10进行分类(DCGAN不是在CIFAR-10上预训练的,而是在Imagenet-1k上训练的,这些特征用于对CIFAR-10图像进行分类 )实验结果如下图所示

当使用大量特征图(4800)时,K-means可达到80.6%的准确率,DCGAN达到了82.8%的准确率,超过了所有基于K均值的方法。值得注意的是,与基于K-means的技术相比,鉴别器的特征图要少得多(最高层为512),但由于有4×4个空间位置的多个层,鉴别器确实会导致更大的总特征向量大小。DCGANs的性能仍然低于样本CNN。
六、操纵生成器表示
1.忘记画某些物体
除了鉴别器学习的表征外,还有一个问题,即生成器学习什么表征。采样的质量表明,生成器可以学习主要场景组件(如床、窗、灯、门和其他家具)的特定对象表示。使用这个简单的模型,从所有空间位置删除权重大于零的所有特征图。然后在去除和不去除特征映射的情况下生成随机新样本。从下图可以看到,上面一行图片都是有窗户的,下面一行通过语义遮罩的方式拿掉了窗户,有趣的是网络大多忘记在卧室中绘制窗口,而是用其他对象替换它们。

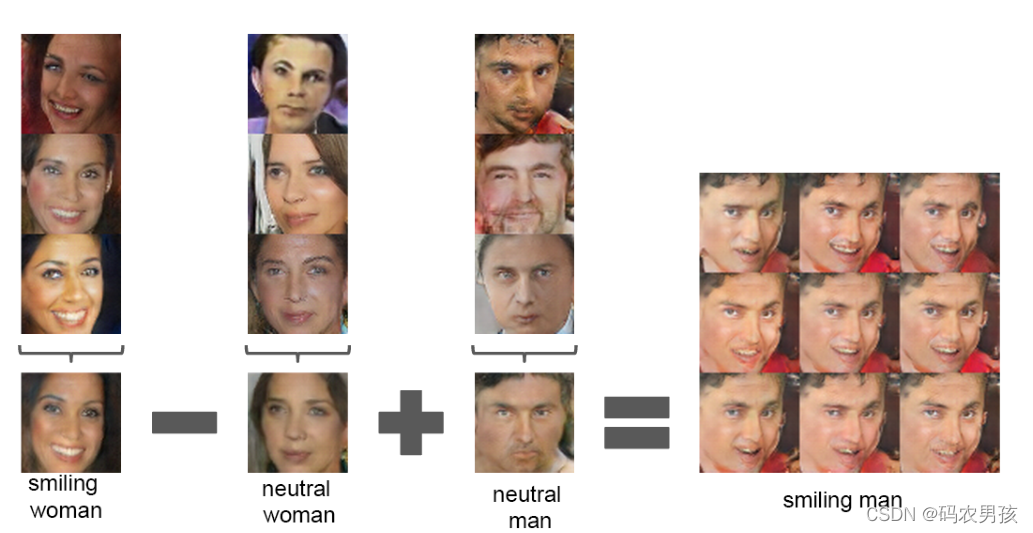
2.人脸样本的矢量算法
简单的算术运算揭示了表征空间中丰富的线性结构,一个典型的例子表明
the vector(”King”) - vector(”Man”) + vector(”Woman”)
将该思想引入到图像生成当中,实验结果效果如下:

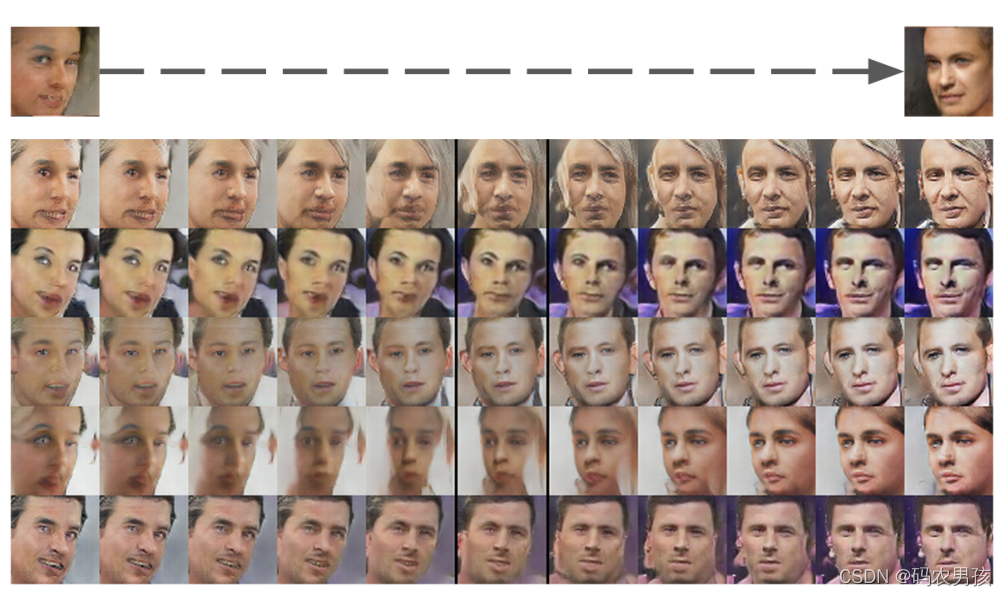 一个“转向”向量是从四个平均的左看和右看的人脸样本中创建的。通过向随机样本添加沿该轴的插值,我们能够可靠地变换它们的姿势。
一个“转向”向量是从四个平均的左看和右看的人脸样本中创建的。通过向随机样本添加沿该轴的插值,我们能够可靠地变换它们的姿势。
七、结论和今后的工作
文章提出了一套更稳定的生成性对抗网络训练体系结构,并证明了对抗性网络能够学习良好的图像表示,用于监督学习和生成性model。但是仍然存在一些不稳定性——随着模型训练时间的延长,它们有时会将滤波器子集折叠为单一振荡模式。需要进一步的工作来解决这一不稳定因素。我们认为,将这个框架扩展到其他领域,比如视频(用于帧预测)和音频(用于语音合成的预训练功能)应该是非常有趣的。进一步研究学习到的潜在空间的性质也会很有趣。 当我们训练一个模型的数据集不够的时候,非常建议大家利用DCGAN来对我们的实验数据集进行扩充!
八、应用
1. GAN本身是一种生成式模型,所以在数据生成上用的是最普遍的,最常见的是图片生成,常用的有DCGAN WGAN,BEGAN,个人感觉在BEGAN的效果最好而且最简单。
2. GAN本身也是一种无监督学习的典范,因此它在无监督学习,半监督学习领域都有广泛的应用,比较好的论文有Improved Techniques for Training GANs、Bayesian GAN(最新)
3. 不仅在生成领域,GAN在分类领域也占有一席之地,简单来说,就是替换判别器为一个分类器,做多分类任务,而生成器仍然做生成任务,辅助分类器训练。
4. GAN可以和强化学习结合,目前一个比较好的例子就是序列对抗网络Seq GAN。
5. 目前比较有意思的应用就是GAN用在图像风格迁移,图像降噪修复,图像超分辨率了,都有比较好的结果,详见pix2pix GAN 和cycle GAN。但是GAN目前在视频生成上和预测上还不是很好。
6. 目前也有研究者将GAN用在对抗性攻击上,具体就是训练GAN生成对抗文本,有针对或者无针对的欺骗分类器或者检测系统等等,但是目前没有见到很典范的文章。
九、其他知识
1.无监督表征学习的经典方法是对数据进行聚类(例如k-means),另一种方法是训练自动编码器(auto-encoder)还有深度置信网络。
2.生成图像模型大致可以分为两类:参数模型和非参数模型
非参数模型:通常从现有图像数据库中进行匹配,通常是匹配patch of images
参数模型:①生成图像的变分采样方法(variational sampling),缺点是会出现模糊图像
②使用迭代的正向扩散过程生成images
③GAN生成,但是噪声多。拉普拉斯金字塔扩展后得到了更高质量图像,但仍有噪声产生的影响。
④递归网络和反卷积网络方法
3. 判别式模型: • 线性回归 • 逻辑回归 • K近邻(KNN) • 支持向量机(SVM) • 决策树 • 条件随机场(CRF) • boosting方法
4. 生成式模型: • 朴素贝叶斯 • 混合高斯模型 • 隐马尔科夫模型(HMM) • 贝叶斯网络 • 马尔可夫随机场 • 深度信念网络(DBN) • 变分自编码器
十、数据集不足时的处理方法
具体到图像分类任务中,在保持图像类别不变的前提下,可以对训练集中的每一幅图像进行一下变换:
- 一定程度内的随机旋转、平移、缩放、剪裁、填充、左右翻转等,这些变换对应着同一个目标在不同角度的观察结果。
- 对图像中的像素添加噪声扰动,比如椒盐噪声、高斯白噪声等。
- 颜色变换。
- 改变图像的亮度、清晰度、对比度、锐度等。
除了直接在图像空间进行变换,还可以先对图像进行特征提取,然后在图像的特征空间内进行变换,利用一些通用的数据扩充或上采样技术,例如SMOTE(Synthetic Minority Over-sampling Technique)算法。抛开上述这些启发式的变换方法,使用生成模型也可以合成一些新样本,例如当今非常流行的生成式对抗网络模型。
十一、实战
DCGAN实战(1)---生成MNIST手写数字代码实现pytorch版
十二、总结
如果将目前对于GAN的研究方向进行划分的话,可以大致分为以下两个方向:
1.对各种GAN的实际应用研究,比如有意思的应用在图像风格的迁移:pix2pixGAN和CycleGAN
可参考:1.GAN系列之 pix2pixGAN 网络原理介绍以及论文解读
2.GAN实战之Pytorch使用pix2pixGAN生成建筑物Label to Facade
3.一文看懂CycleGAN网络原理以及论文精华解读 4. GAN项目实战 使用CycleGAN将苹果变成橙子Pytorch版
2.关于如何稳定GAN的训练进行研究,可参考WGAN
一文看懂GAN系列之WGAN(Wasserstein GAN)原理

