文章目录
- 第一部分
- 一、 Features:Textual Inversion(文本反转)
- 1.1 Textual Inversion 简介
- 1.1.1 摘要
- 1.1.2 算法
- 1.1.3 模型效果
- 1.2 Textual Inversion of webai
- 1.2.1 预训练embedding用于图片生成
- 1.2.2 训练embedding
- 1.2.3 Finding embeddings online
- 1.2.4 Hypernetworks
- 二、 Features: Negative prompt
- 三、Xformers依赖
- 四、NVidia GPUs安装
- 4.1 自动安装
- 4.2 自定义安装
- 五、命令行参数和优化
- 六、安装和使用自定义脚本
- 第二部分 kaggle notebook
- 一、模型部署
- 1.1 kaggle notebook
- 1.2 colab、windows部署
- 二、进阶教程
- 2.1 Prompt运用规则及技巧
- 2.2 Model资源
- 2.3 Embedding/ Hypernetwork使用及训练
- 2.4 Dreambooth使用及训练
- 2.5 插件介绍
第一部分
本文翻译自stable-diffusion-webui官方文档
一、 Features:Textual Inversion(文本反转)
Textual Inversion:论文、博客,知乎贴、《paper笔记》
1.1 Textual Inversion 简介
1.1.1 摘要
文生图模型为通过自然语言指导创作提供了前所未有的自由。然而,目前尚不清楚如何运用这种自由来生成特定独特概念的图像,修改其外观,或将其合成新角色和新场景。换言之,要把现实中的一些新概念(new concept)引入到生成中,单从文本出发还是不够的。
本文提出了 personalized text-to-image generation,即个性化的文转图生成。可以基于文本+用户给的3-5张图(“new concepts”)来生成新的图像。
提出了textual inversions,用于把图片概念转换成pseudo-words(伪单词)。然后一起合并到prompt中,从而生成一些具备这样概念的图片。
1.1.2 算法
在大多数文生图模型的文本编码阶段,第一步是将prompt 转换为数字表示,而这通常是通过将words转换为tokens来完成的,每个token相当于模型字典中的一个条目(entry)。然后将这些entries转换为embeddings进行训练。
我们发现了可以添加用户提供的special token (S*,表示新概念)来作为新的embedding。然后,将这个embedding link到新的伪单词,伪单词可以同其它词一样被合并到新的句子中。在某种意义上,我们正在对冻结模型的文本嵌入空间进行反转,所以我们称这个过程为Textual Inversion(文本反转)。
我的理解,之前都是将文本编码为embedding进行训练,而Textual Inversion是将用户提供的图片(“A photo of S*”)以embedding的形式链接到某个伪单词上来表示一种概念。即embedding→文本,和之前是相反的过程。
模型结构如下图所示:
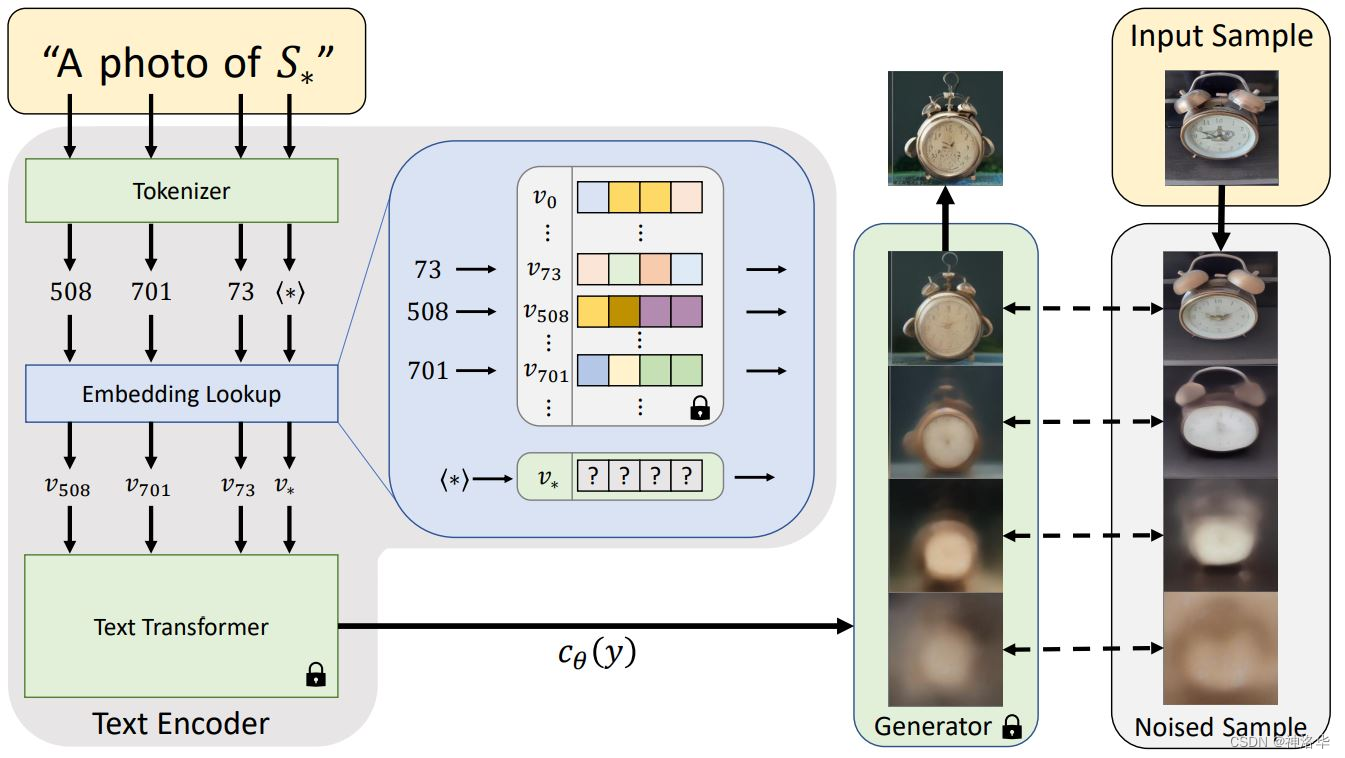
- 本文是基于latent diffusion做的,只改进了其中text encoder部分的词表部分,添加
S*来表达新概念,其它token的embedding不变,从而实现与新概念的组合。 - 为了训练
S*对应的文本编码v*,使用prompt “A photo of S*”生成新的图片,我们希望这个概念生成图片和用户给的图片相符合,从而学习到v*这个新概念。学到之后就可以利用S*来做新的生成了。 - 损失函数:让通过这个句子prompt产生的图片和用户给的small sample(3~5张图)越近越好:
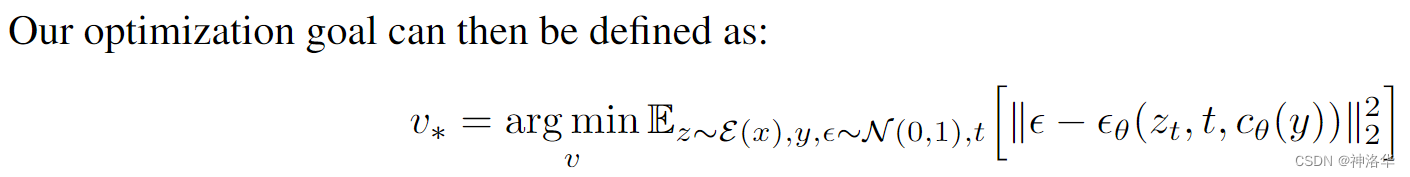
1.1.3 模型效果
- Image Variations:相似图生成
因为embedding 的学习目标本身就是要生成一摸一样的图片,所以本文的相似图生成效果很好:

- Text-guided synthesis(文本引导生成)
下面是基于学到的新概念的生成:
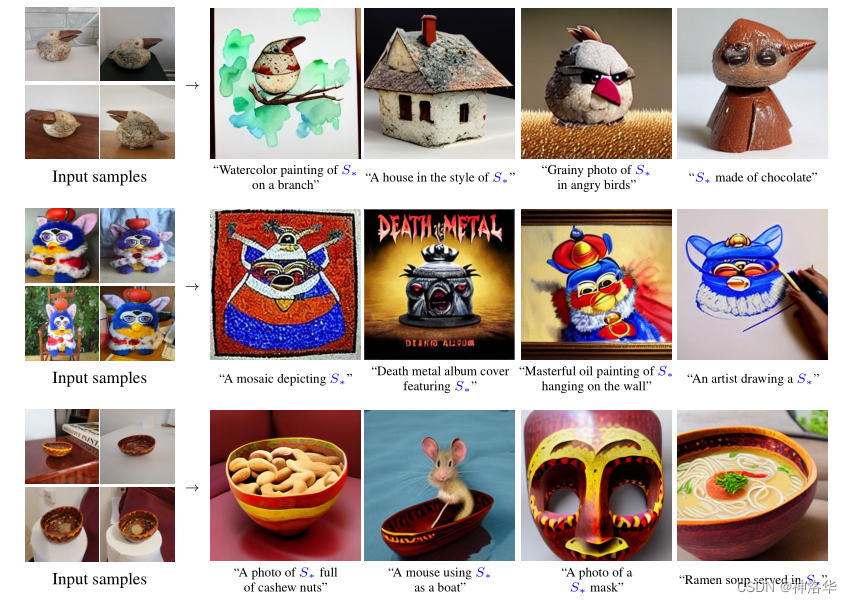
和CLIP guided的方法的对比:最相近的工作是PALAVRA——把新概念图片先得到image embedding,再用对比学习的方法转成text embedding,然后再进行生成,而本文是直接学习pseudo-word。在guided diffusion中,有init image的生成效果会好很多,但是还是会出现原来图片变形的问题。
- Style transfer(风格迁移)
通过in the style of 这样的prompt可以实现风格迁移:

-
Concept compositions(概念组合)
不同图片概念,组合起来进行生成,Unfortunately, this doesn’t yet work for relational prompts, so we can’t show you our cat on a fishing trip with our clock.

-
Downstream applications
我们的伪词适用于下游模型。例如,将旧照片添加一些新元素来增加它们的趣味性:(把第二排图片中蓝色部分替换为第一排的元素)

-
Reducing Biases(减少偏见,略)
1.2 Textual Inversion of webai
参考《Features:Textual Inversion》
webai允许用户使用Textual Inversion 将自己的图片进行训练,得到一个embedding(预训练的embedding),用于指导新图片的生成。这个预训练embedding是一个.pt或.bin文件(前者是原始作者使用的格式,后者是diffusers library使用的格式)。
1.2.1 预训练embedding用于图片生成
将预训练好的embedding(嵌入)放入embeddings目录,并在prompt中使用其文件名,无需重新启动程序即可生成新的图片。例如,下面是webai作者在WD1.2模型上,用53张图片(增强成119张)训练19500步后得到的Usada Pekora embedding。

您可以在一个prompt中组合多个embedding:(相比上图prompt多加了一个词——mignon)

使用embedding生成新的图片时的模型,最好和训练这个embedding时的模型保持一致,否则生成效果可能不好。下面是WD1.2模型训练的usada pekora embedding,用在stable diffusion 1.4上进行生成的效果:(prompt和参数保持不变,但是生成的图片不是最开始的风格了)

1.2.2 训练embedding
-
embedding训练说明
- 该功能非常原始,使用风险自负
- 创建一个新的empty embedding,选择待训练图像的目录,进行embedding训练。
- 启用半精度浮点运算,但需试验开启前后效果是不是一样好。如果显存足够,使用
--no-half --precision full更安全 - 用于UI自动运行图像预处理的部分。
- 中断后重启训练,不会丢失任何数据
- 不支持batch sizes 或 gradient accumulation(梯度累积,用于显存不足),不支持–lowvram 和 --medvram flags。
-
参数说明
Creating an embeddingname:embedding的文件名。后续在prompt使用这个embedding时就用这个名字。Initialization text(初始化文本):用于新建empty embedding的初始化。- 新建后会用Initialization text的embedding填充empty embedding。也就是如果你创建empty embedding后又不训练,那么这个embedding和Initialization text的embedding是一样的。
- 比如你新建一个名为“zzzz1234”的empty embedding,然后选“tree”这个词作为Initialization text。那么不进行任何训练时,“zzzz1234”和“tree”的embedding是一样的
Number of vectors per token:empty embedding的size。- 比如webai模型默认prompt的长度上限是75个token,如果设置Number of vectors per token=16,那么你将这个empty embedding加入prompt后,就只能再写75-16=59个token了。
- empty embedding的size越大,就可以融合更多的主题信息(概念信息),相应的,你就需要更多的图片,才能训练好这个empty embedding。
Preprocess:将目录下的图片进行Textual Inversion,并将结果写入另一个目录Source directory:包含图像的目录Destination directory:将写入结果的目录Create flipped copies:对于每个图像,还要写入其镜像副本Split oversized images into two:将过大的图像拆分为两张(短边与所需分辨率相匹配,两张图片可能相交)Use BLIP caption as filename:使用BLIP模型向文件名添加标题。
Training an embeddingEmbedding:从下拉列表中选择要训练的嵌入。Learning rate:学习率,设置得太高,可能会破坏embedding- 比如在训练中提示Loss:nan,训练失败)。使用默认值时,不会发生这种情况。
- 设置多个学习率,比如
0.005:100, 1e-3:1000, 1e-5表示前100步lr=0.005,101-1000步时lr=1e-3,最后lr=1e-5。
Dataset directory:待训练图像的目录。Log directory:样本图像和部分训练的嵌入副本将写入此目录。Prompt template file: text file with prompts,每行一个,用于训练模型。- 训练风格使用
style.txt(只需要3、5张图片),训练主题使用subject.txt(Number of vectors per token越大,需要的图片就越多)。文件中可以使用以下tag:[name]:embedding名称[filewords]:来自数据集图像文件名的单词。有关更多信息,请参见下文。
- 有关如何使用这些文件,请参阅
textual_inversation_templates目录中的文件。
- 训练风格使用
Max steps:Max steps步后完成训练。模型训练一张图片是一个step。如果您训练中断后重启,会保留step数。Save images with embedding in PNG chunks:每次生成图像时,都会将其与最近记录的嵌入合并,并以可以作为图像共享的格式保存到image_embeddings中,然后将其放入嵌入文件夹并加载。Preview prompt:如果不为空,此prompt将用于生成预览图;如果为空,the prompt from training will be used。
filewords:[filewords]:提示模板文件( prompt template)的标签,默认下去掉图片文件名前面的数字和破折号(-)就是[filewords],比如图片000001-1-a man in suit.png的[filewords]就是a man in suit,是一个文本。这个文本可用在prompt中。- 可以使用选项
Filename word regex和Filename join string更改文件名中的文本。(感觉没必要,详情看原文档)
- 第三方库
webai训练embeddings时还使用了Stable-textual-inversion_win和InvokeAI这两个github仓库。还有一些是关于diffusers library或者colab上训练的选项。
1.2.3 Finding embeddings online
- huggingface concepts library :有很多不同的emb
- 16777216c:NSFW,动漫艺术家风格。
- Catoroboto:一些匿名的动画embedding。
- viper1:NSFW,furry girls。
- anon’s embeddings -NSFW:动漫艺术家。
- rentry:包含多种SD模型的 Textual Inversion emb

1.2.4 Hypernetworks
Hypernetworks是在不影响模型权重的情况下微调模型的概念。目前是在textual inversion选项卡里训练hypernets,训练方式和textual inversion相同,但是学习率很低,比如5e15或者5e-6。这部分可参考《Hypernetworks训练指南》。
Unload VAE and CLIP from VRAM when training:这个选项卡允许降低预览图生成速度来减少显存。
二、 Features: Negative prompt
Negative prompt用于指定不想生成的内容,使用Negative prompt可以消除了Stable Diffusion的常见畸形,比如多余的肢体。Negative prompt可单独使用(即不用 prompt)。
要使用Negative prompt,只需以下步骤:
# prompts = ["a castle in a forest"]
# negative_prompts = ["grainy, fog"]
c = model.get_learned_conditioning(prompts)
uc = model.get_learned_conditioning(negative_prompts)
samples_ddim, _ = sampler.sample(conditioning=c, unconditional_conditioning=uc, [...])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
采样器(sampler)将比较prompt生成的图片和Negative prompt生成的图片之间的差异,并是最终生成结果逼近前者,远离后者。下面是一个演示:
- 原始图片有雾状(fog)、颗粒感(grainy,画质低)。Negative prompt为fog后雾状没了但是生成奇怪的紫色
- Negative prompt为fog,grainy, purple,没有雾状,画质高,也没有奇怪的紫色了。




三、Xformers依赖
Xformers库可以加速图像的生成(可选),没有适用于Windows的二进制文件(除了一个特定的配置外),可自行构建。
- linux上构建Xformers的指南:
#切换到webui根目录
source ./venv/bin/activate
cd repositories
git clone https://github.com/facebookresearch/xformers.git
cd xformers
git submodule update --init --recursive
pip install -r requirements.txt
pip install -e
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- Windows上构建xFormers(见原文档)
四、NVidia GPUs安装
在尝试安装之前,请确保满足所有必需的依赖项。
依赖项包括:
- 安装
Python 3.10.6和git- 运行
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git下载webai项目,后续可以使用git pull命令更新项目。(windows用户安装git for windows后,在某个文件夹里右键单击选择Git Bash here打开git,运行此命令下载项目。)- 下载Stable Diffusion 模型文件(
.ckpt)、sd-v1-4.ckpt放在项目根目录下的models/Stable-diffusion文件夹里。- Stable-diffusion 2.x 版本的模型,需要下载配套的
.yaml配置文件,并放在.ckpt同名的文件夹中:768-v-ema.ckpt config、512-base-ema.ckpt config、512-base-ema.ckpt config
4.1 自动安装
- windows:运行
webui-user.bat,如果运行失败可以参考Troubleshooting 。 - Linux:项目根目录下运行:
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)
python launch.py可自动运行模型,运行时可以使用一些命令参数,比如:
python launch.py --opt-split-attention --ckpt ../secret/anime9999.ckpt
- 1
4.2 自定义安装
更改webui-user.sh中的变量,并运行bash webui.sh,接下来自定义安装步骤、AMD GPUs安装、见原文档。此文档还有WSL2安装,conda安装等。
更多关于安装的详细教程,可以参考帖子《使用stable-diffusion-webui部署NovelAi/Stable Diffusion1.4 /1.5/2.0 保姆级教程、命令解释、原理讲解(colab、windows、Linux )》
五、命令行参数和优化
| 命令行参数 | 解释 |
|---|---|
--share | online运行,也就是public address |
--listen | 使服务器侦听网络连接。这将允许本地网络上的计算机访问UI。 |
--port | 更改端口,默认为端口7860。 |
--xformers | 使用xformers库。极大地改善了内存消耗和速度。Windows 版本安装由C43H66N12O12S2 维护的二进制文件 |
--force-enable-xformers | 无论程序是否认为您可以运行它,都启用 xformers。不要报告你运行它的错误。 |
--opt-split-attention | Cross attention layer optimization 优化显着减少了内存使用,几乎没有成本(一些报告改进了性能)。黑魔法。默认情况下torch.cuda,包括 NVidia 和 AMD 卡。 |
--disable-opt-split-attention | 禁用上面的优化 |
--opt-split-attention-v1 | 使用上述优化的旧版本,它不会占用大量内存(它将使用更少的 VRAM,但会限制您可以制作的最大图片大小)。 |
--medvram | 通过将稳定扩散模型分为三部分,使其消耗更少的VRAM,即cond(用于将文本转换为数字表示)、first_stage(用于将图片转换为潜在空间并返回)和unet(用于潜在空间的实际去噪),并使其始终只有一个在VRAM中,将其他部分发送到CPU RAM。降低性能,但只会降低一点-除非启用实时预览。 |
--lowvram | 对上面更彻底的优化,将 unet 拆分成多个模块,VRAM 中只保留一个模块,破坏性能 |
*do-not-batch-cond-uncond | 防止在采样过程中对正面和负面提示进行批处理,这基本上可以让您以 0.5 批量大小运行,从而节省大量内存。降低性能。不是命令行选项,而是使用–medvramor 隐式启用的优化–lowvram。 |
--always-batch-cond-uncond | 禁用上述优化。只有与–medvram或–lowvram一起使用才有意义 |
--opt-channelslast | 更改 torch 内存类型,以稳定扩散到最后一个通道,效果没有仔细研究。 |
其它详见原文档。
六、安装和使用自定义脚本
要安装自定义脚本,请将它们放入scripts目录,然后单击设置选项卡底部的Reload custom script按钮。安装后,自定义脚本将出现在txt2img和img2img选项卡的左下方下拉菜单中。以下是Web UI用户创建的一些著名的自定义脚本:
- prompt改进脚本:https://github.com/ArrowM/auto1111-improved-prompt-matrix
- 本脚本支持prompt矩阵格式,用于一次生成多个prompt,每个prompt可生成多张图片(脚本代码)
- 使用
<>创建一个prompt矩阵,矩阵中用|进行分隔。例如a <corgi|cat> wearing <goggles|a hat>,表示4个prompt:a corgi wearing goggles,a corgi wearing a hat,a cat wearing goggles,a cat wearing a hat。 - 如果设置
batch count > 1,忽略 batch size,每个seed,每个prompt都会进行生成。

txt2img2img:https://github.com/ThereforeGames/txt2img2img
大大提高任何角色/主题的可编辑性,同时保持其相似性。该脚本的主要动机是提高通过Textual Inversion.创建的embedding的可编辑性。
txt2mask:https://github.com/ThereforeGames/txt2mask
可以使用文本指定mask修复部分,而不是用笔刷。
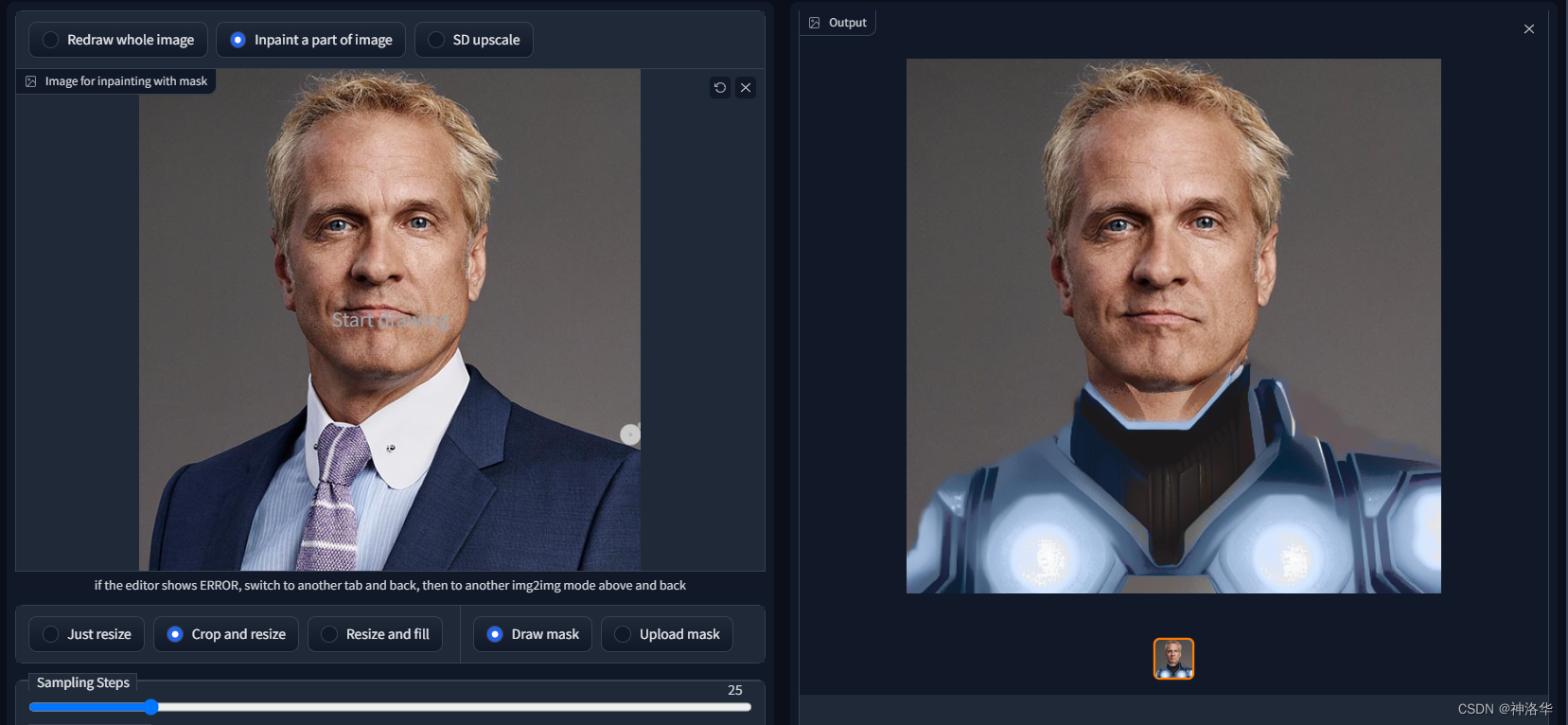
Mask drawing UI:https://github.com/dfaker/stable-diffusion-webui-cv2-external-masking-script
提供CV2支持的本地弹出窗口,允许在处理前添加掩码。Img2img Video:https://github.com/memes-forever/Stable-diffusion-webui-video
使用img2img,依次生成图片。Seed Travel:https://github.com/yownas/seed_travel
选择多个种子,并在它们之间生成插值图像序列,或者是一个视频,点此查看示例。Advanced Seed Blending:https://github.com/amotile/stable-diffusion-backend/tree/master/src/process/implementations/automatic1111_scripts
可以设定seed权重,例如:seed1:2, seed2:1, seed3:1,也可以使用浮点数:seed1:0.5, seed2:0.25, seed3:0.25。- Prompt Blending:https://github.com/amotile/stable-diffusion-backend/tree/master/src/process/implementations/automatic1111_scripts
支持多个prompt的加权组合,例如:Crystal containing elemental {fire|ice},也支持嵌套:Crystal containing elemental {{fire:5|ice}|earth} - Animator:https://github.com/Animator-Anon/Animator
适用于制作视频
余下内容有空再写了。下面是模型部署和应用的一些资源收集贴,也没有好好整理,感觉太麻烦了。
第二部分 kaggle notebook
一、模型部署
- 此笔记本基于stable-diffusion-webui项目,默认使用momoko模型,点此即可打开。
1.1 kaggle notebook
- 下载项目
#测试GPU
!nvidia-smi
#下载stable-diffusion-webui
%cd /kaggle/working/
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
#在models文件夹下新建新建hypernetworks目录
!mkdir -p /kaggle/working/stable-diffusion-webui/models/hypernetworks
%cd /kaggle/working/stable-diffusion-webui/models/Stable-diffusion
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
切换喜欢的模型,默认是momoko
- 更改模型的默认方法是,将input文件夹中你需要的模型移入
working/stable-diffusion-webui/models/Stable-diffusion/文件夹下 - 也可以使用ChangeModel函数更换模型,这种方式是更改读取模型的路径,所以不需要复制模型文件本体。如果模型生成图片老是有点灰色,在下面红色选项框中下拉选择VAE(前提是将模型对应的VAE文件复制到/kaggle/working/stable-diffusion-webui/models/VAE文件夹下)
- momoko模型(色彩鲜艳,质量很高)和Anything模型的介绍,可参考视频《一键搭建代码更新anything及momoko-p模型》

-
更多模型可见《Stable Diffusion Models》
- 更改模型的默认方法是,将input文件夹中你需要的模型移入
下面是将
/kaggle/working/stable-diffusion-webui/modules/sd_models.py中,默认的模型读取地址model_dir = ".*?"用正则表达式替换为 model_dir = “/kaggle/input/{}”,其中 {} 被替换为变量 modelPath 的值。替换后将该内容写入sd_models.py文件。
#最新切换模型方法
import re,os,shutil
def ChangeModel(modelPath):
with open ('/kaggle/working/stable-diffusion-webui/modules/sd_models.py','r') as f:
tt = f.read()
tt = re.sub('model_dir = ".*?"','model_dir = "/kaggle/input/{}"'.format(modelPath),tt)
with open ('/kaggle/working/stable-diffusion-webui/modules/sd_models.py','w') as f:
f.write(tt)
#在你想要使用的模型对应的代码前去掉#,其他模型的对应代码前加上#
chooseModel = ''
#二次元
#chooseModel='animefulllatestckpt' #1. 7g animefull-final-latest,二次元和写实风兼有
#chooseModel='animefullfinalpruned' #2. 4g animefull-final-pruned,二次元风格
#chooseModel='anythingv3' #3. 7g Anything-v3.0 Novel AI最新模型
chooseModel='momoko' #4. momoko
#chooseModel='mignon' #5. Mignon
#chooseModel='moxing' #6. MomoCha&Mecha
#chooseModel='nicenice' #7. nice
#写实风
#chooseModel='stable-diffusion-1-5' #1. stable-diffusion 1.5
#chooseModel='inpainting' #2. stable diffusion 1.5 inpainting,(专用于inpaint的模型)
#chooseModel='stable-diffusion-2-768' #3. stable diffusion 2.0
#chooseModel='redshiftdiffusionv1' #4. edshift diffusion v1
#chooseModel='modf222' #5. f222
#chooseModel='insins' #6. ins写真风
#chossModel='realyolyjijiajohn' #7. 融合多个模型的写实风
model_list=['momoko','animefullfinalpruned','redshiftdiffusionv1','mignon','nicenice','insins']
if chooseModel in model_list:
try:
# shutil.copytree(src,dst)。将文件夹 src 中全部文件递归复制到 dst ,dst 若不存在时系统自动创建~
shutil.copytree('/kaggle/input/tagcomplete3w2cn/wd14-tagger/wd14-tagger','/kaggle/working/stable-diffusion-webui/extensions/wd14-tagger')
except:
pass
else:
try:
# 递归删除整个文件夹下所有文件,包括此文件夹
shutil.rmtree('/kaggle/working/stable-diffusion-webui/extensions/wd14-tagger/')
except:
pass
ChangeModel(chooseModel)
print('模型已切换成:'+chooseModel)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 安装扩张功能和插件、脚本
a. 扩展功能:
!apt install -y aria2 # Aria2是一个命令行下载器,可从百度网盘下载资源
# 安装animefull-final-latest (可选)
!aria2c -d /kaggle/working/stable-diffusion-webui https://cloudflare-ipfs.com/ipfs/bafybeiav3j7npiuewbel3mi32l3sidgkw54kuleosbhxmdvddbnvtfi7yu/config.yaml
#!aria2c https://pub-2fdef7a2969f43289c42ac5ae3412fd4.r2.dev/animefull-latest.ckpt
#!aria2c -d /kaggle/working/stable-diffusion-webui/models/Stable-diffusion https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml
# 安装embeddings (可选)
!aria2c https://cloudflare-ipfs.com/ipfs/bafybeie3hdjchxs5tz4n75bos53nhcklslguxchdurc2ynrzcfv2kwyklu/embeddings.tar
!tar xvf embeddings.tar -C /kaggle/working/stable-diffusion-webui/embeddings && rm -rf embeddings.tar
# 安装hypernetwork (可选)
!aria2c https://cloudflare-ipfs.com/ipfs/bafybeiduanx2b3mcvxlwr66igcwnpfmk3nc3qgxlpwh6oq6m6pxii3f77e/_modules.tar
!tar xvf _modules.tar -C /kaggle/working/stable-diffusion-webui/models/hypernetworks && rm -rf _modules.tar
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
b. 安装插件
- 参考《Stable-diffusion-webui 插件拓展及依赖汇总》、插件翻译列表((含主要插件)
- 详细文档和项目地址见《a1111-sd-webui-tagcomplete》,也可参考帖子《Prompt自动补全脚本》
- tagcomplete:本脚本为 stable-diffusion-webui的自定义脚本,能在输入Tag时提供booru风格(如Danbooru)的TAG自动补全。因为有一些模型是基于这种TAG风格训练的(例如Waifu Diffusion),因此使用这些Tag能获得较为精确的效果。
- DeepDanbooru:DeepDanbooru是一个动漫风格的女孩图像标签评估系统,在webui的img2img选项页,第一次点击deepdanbooru时程序会自动下载pt检查点文件并调用。
- images-browser:这是一个图像浏览器,用于浏览过去生成的图片,查看其生成的信息,将提示发送到txt2img或img2img,将图像收集到您的“收藏夹”文件夹,删除您不再需要的图像,您还可以在计算机中的任何文件夹中浏览图像
- webUI简体中文语言包,简体中文翻译扩展,适用于 stable diffusion webui。
- Aesthetic Gradients
- 美学权重功能(以插件形式提供),借助该功能,可以在保持作品原始的总体构图上提高美观度。
- 结合hypernetwork使用效果更佳
- 支持txt2img和img2img
将上述插件下载后复制到extensions文件夹,即可完成安装。
%cd /kaggle/working/stable-diffusion-webui/extensions
# 下载安装webUI简体中文语言包,tagcomplete补全Tag插件、images-browser
!git clone https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN
!git clone https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
!git clone https://github.com/yfszzx/stable-diffusion-webui-images-browser
- 1
- 2
- 3
- 4
- 5
c. 安装脚本
webui也提供众多脚本,详细介绍参考官方文档Custom Scripts。下面选了一个提示词矩阵脚本。
- 本脚本支持prompt矩阵格式,用于一次生成多个prompt,每个prompt可生成多张图片(脚本代码)
- 使用
<>创建一个prompt矩阵,矩阵中用|进行分隔。例如a <corgi|cat> wearing <goggles|a hat>,表示4个prompt:a corgi wearing goggles,a corgi wearing a hat,a cat wearing goggles,a cat wearing a hat。 - 如果设置
batch count > 1,忽略 batch size,每个seed,每个prompt都会进行生成。
- 使用
- 注意:使用提示词矩阵脚本,但是其实没有设置提示词矩阵,图片生成时会出现报错
%cd /kaggle/working/stable-diffusion-webui/scripts/
!git clone https://github.com/ArrowM/auto1111-improved-prompt-matrix
- 1
- 2
- 启动模型,开始生成图片
参考《使用stable-diffusion-webui搭建AI作画平台使用stable-diffusion-webui搭建AI作画平台》
--share参数 会得到一个以.app.gradio结尾的链接,这是在协作中使用该程序的预期方式。(不加--share没法远程使用)- 安装并启动stable-diffusion-webui,成功后打开public URL就可以生成图片了
- 报错No module ‘xformers‘. Proceeding without it是因为没装xformers,运行以下代码安装
%cd /kaggle/working/stable-diffusion-webui
# 加载模型。sed -i表示将字符串直接写入sd_models.py文件
!sed -i 's/map_location="cpu"/map_location="cuda"/g' /kaggle/working/stable-diffusion-webui/modules/sd_models.py
import gc
gc.collect()
# use normal stable-diffusion
!COMMANDLINE_ARGS="--share --gradio-debug --config config.yaml --disable-safe-unpickle " REQS_FILE="requirements.txt" python launch.py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
将生成的图片进行打包,方便下载。
!zip -q -r output.zip /kaggle/working/stable-diffusion-webui/outputs
!mv /kaggle/working/stable-diffusion-webui/output.zip /kaggle/working/output.zip
- 1
- 2
- webui界面介绍
通过前面的安装配置,你就可以通过你设置的端口进行访问。访问内容后分为几个大的模块;
- txt2img — 标准的文字生成图像;
- img2img — 根据图像成文范本、结合文字生成图像;
- Extras — 优化(清晰、扩展)图像;
- PNG Info — 图像基本信息
- Checkpoint Merger — 模型合并
- Textual inversion — 训练模型对于某种图像风格
- Settings — 默认参数修改
此部分请参考知乎贴《模型应用—使用Stable Diffusion UI手册》使用部分。
- 手把手教你在linux中手动编译并安装xformers
1.2 colab、windows部署
详见《部署NovelAi/Stable Diffusion1.4 /1.5/2.0 保姆级教程》
二、进阶教程
2.1 Prompt运用规则及技巧
参考《NovelAI资源及使用技巧收集汇总》、《Stable-diffusion 标签Tag (脸部方法构造)》、元素同典、元素法典、《魔咒百科词典》、《Prompt Magic Tutorial》
-
通用Tag起手式:
- 正向:
masterpiece, best quality, 更多画质词,画面描述 - 反向:
nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
- 正向:
-
越靠前的Tag权重越大;比如景色Tag在前,人物就会小,相反的人物会变大或半身。
-
生成图片的大小会影响Prompt的效果,图片越大需要的Prompt越多,不然Prompt会相互污染。
-
在Stable Diffusion 中使用()英文括号可增加括号中Tag在画面中的权重 x1.1,[]可减小Tag权重x0.91。在NovelAi官网中,使用{}增加权重x1.05。
-
Prompt支持使用emoji,且表现力较好,可通过添加emoji达到表现效果。如😍形容表情,🖐可修手。
-
“+” , “ AND” , “|” 用法:
- “+”和“ AND ”都是用于连接短Tag,但AND两端要加空格。"+“约等于” and "
- “|” 为循环绘制符号(融合符号)
(Prompt A: w1)|(Prompt B: w2)
以上表达适用于WebUI,w1、w2为权重。AI会对A、 B两Prompt进行循环绘制。可往后无限加入Prompt。
-
Prompt格式优化:简易换行三段式表达:
- 第一段: 画质tag,画风tag
- 第二段:画面主体,主体强调,主体细节概括。(主体可以是人、事、物、景)画面核心内容。第二段一般提供人数,人物主要特征,主要动作(一般置于人物之前),物体主要特征,主景或景色框架等
- 第三段:画面场景细节,或人物细节,embedding tag。画面细节内容
-
元素同典调整版语法:
质量词→前置画风→前置镜头效果→前置光照效果→(带描述的人或物AND人或物的次要描述AND镜头效果和光照)*系数→全局光照效果→全局镜头效果→画风滤镜(embedding)
实例展示:

parameters:
Prompt:
(((masterpiece))), best quality, ultra-detailed, extremely detailed CG unity 8k wallpaper,best illustration, an extremely delicate and beautiful,floating,high resolution,
dynamic angle,dynamic pose,(1girl),blue eyes,(multicolored_hair+silver hair:1.3+red hair:1.2+purple hair+yellow hair:1.3+green hair:1.3), white wuxia clothes,neck ribbon, beautiful face,
too many drops of water,cloud,twilight, wide shot,watercolor,
- 1
- 2
- 3
- 4
- 5
Negative prompt:
lowres, bad anatomy, bad hands, text,error, missing fIngers,extra digt ,fewer digits,cropped, worst quality ,low quality,normal quality, jpeg artifacts,signature,watermark, username, blurry, bad feet,fused body,
- 1
Steps: 34, Sampler: DPM++ 2S a, CFG scale: 10.5, Seed: 1351767725, Size: 960x576, Model hash: 925997e9, Eta: 0.68, Clip skip: 2, ENSD: 31337
GFPGAN visibility:1.Upscale: 3, visibility: 1.0, model:ESRGAN_4x
更多内容请看原贴。
也可简单一点,使用chatGPT来实现stable-diffusion描述词生成、让chatGPT帮你AI绘画

2.2 Model资源
使用注意:与ckpt文件同名的vae.pt文件用于稳固该模型的表现,直接放在相同文件夹即可。训练时将该文件改名或移走。并不是所有模型都需要使用vae文件
公开资源:
- https://rentry.org/sdmodels(目前觉得比较全)
- https://cyberes.github.io/stable-diffusion-models/(SD模型)
- https://publicprompts.art/(App Icon Generator,比较有趣想资源)
- https://huggingface.co/ (在网站中检索) 作者:小白随心所欲
2.3 Embedding/ Hypernetwork使用及训练
参考《NovelAI资源及使用技巧收集汇总》、《NovelAI hypernetwork 自训练教程》
2.4 Dreambooth使用及训练
2.5 插件介绍
- Aesthetic-gradients(美术风格embedding)使用
- 素材保证高质量,尺寸不限,随建随用。优化画风,效果同emb和hypernetwork。batch按图片数量填就行。
- 建议图片集尽量挑选画风一致的图片,就算是同一画师,不同的画也有区别。
- X/Y plot(参数对比)
通过设置X轴和Y轴的参数,可以产出参数变化的对比图。
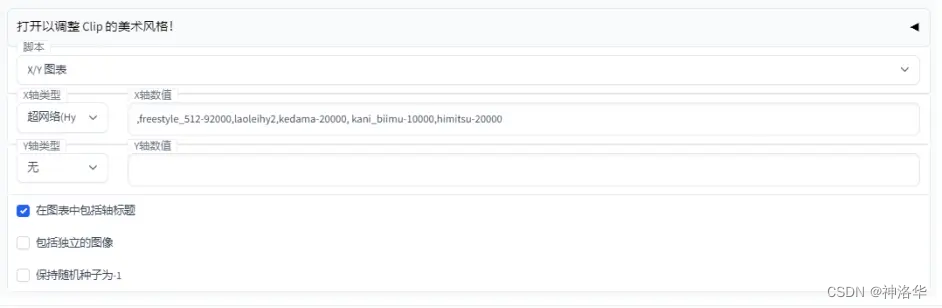
如上图填写X轴为hypernetwork,只需填上hypernetwork的文件名即可。注意,开头逗号和结尾逗号会分别在开头和结尾生成一张效果同none的图片。
