B+Tree的来源
在日常的开发和面试中经常接触的就是InnoDB存储引擎中的B+Tree索引。而学习B+Tree之前先要学习二叉查找树,平衡二叉树,B数这三种数据结构。
二叉查找树
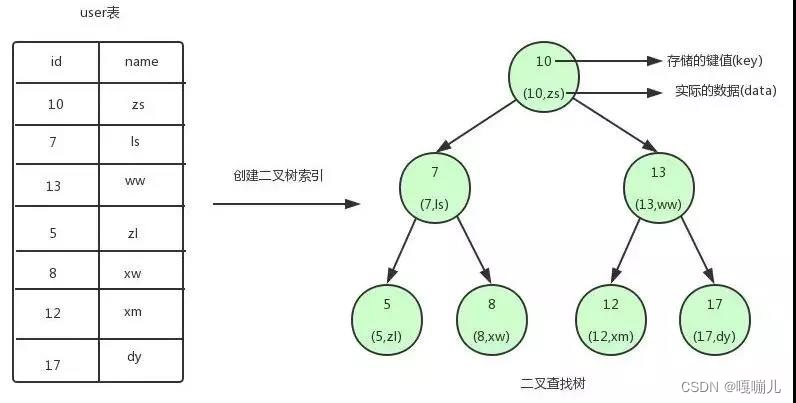
上图就是根据User表创建的二叉查找树的索引。通过图片可知二叉查找树中的每个节点都存储了键(key)和值(data)。key对应的就是表中的id,data对应就是表中的一行数据。
二叉查找树的特点就是任意节点的左子节点的key都小于当前节点的key,右节点的key都大于当前节点key。
应用场景:假定需要查询id为17的用户信息,使用二叉查找树的查询流程是:
1.首先找到根节点,把需要查询的id和当前节点进行比较,发现17大于当前节点的key(10)。根据二叉查找树的特点接下来需要把根节点的右子节点作为当前节点。
2.继续使用17和当前节点的key(13)进行比较。原理和步骤1同理。
3.继续使用17和当前节点的key(17)进行比较,发现满足查询条件。那么就用当前节点中取出data(id=17,name=dy)
通过分析查找流程可知查询id=17的数据(data)一共进行了三次匹配就可以完成。如果不使用二叉查找树那么对表逐个比较那么就需要7次才能匹配到。
平衡二叉树
上述已经学习了二叉查找树这种数据结构,但是在极端的情况下二叉查找树会退化成单向链表。

如果数据比较极端,生成了上面的这种二叉查找树,那么刚才的id=17的查询会发现在二叉查找树的结构中依然需要查找7次。那么这样就和全表扫描没有任何区别。并不一定说极端情况就是退化成单向链表,只要二叉查找树的高度过高并且不平衡的情况下效率就是很低。所以这种结构就存在很大的缺陷,为了解决这个问题就引出平衡二叉树。平衡二叉树的特点就是满足二叉查找树的基础上,添加一个新的要求。每个节点的左右子树的高度差距不能超过1。

PS:如果对数据进行添加,修改和删除操作导致平衡二叉树不平衡时,那么平衡二叉树就根据树上节点的数据进行保持平衡。
PS:平衡二叉树相对于二叉查找树来说,效率更加稳定。
B树
由于数据的核心就是不丢失,所以数据库中的数据一般都是存储在磁盘上。但是存储磁盘最大的问题就是速度很慢,相比较内存来说最小差距也在百倍左右,在极端情况下可能差距上万倍。而性能的差距主要原因就是频繁的IO操作。那么如果当表中的数据量比较大的时候那么平衡二叉树就会出现n层的情况(平衡二叉树和二叉查找树有共同的特点,就是节点上存储数据)。

通过上图可知在数据量比较大的情况下平衡二叉树也存在很大的性能问题。造成这样问题的核心原因就是单个节点存在单个key和data。那么为了解决平衡二叉树存在的这个问题就需要从单节点存储的数据入手。
创建一种单节点可以存储多个key和data的平衡树。这就是B树。

PS:存储单元称之为页(页其实就是磁盘的每个磁盘块)
通过上述图片可以得知一个结果,就是B树相较于平衡二叉树来说最大的改变就是每个节点可以存储更多的key和data。并且每个节点(页)可以拥有更多的子节点,这样的设计就造成了树的高度降低了。由于树的高度降低了那么在查找数据的时候读取磁盘的次数就减少了(降低IO操作)。那么效率也就提升了。
应用场景: id=29的数据。
1.首先找到页1.判断29是页1中的17和35的区间。那么就根据页1中P2的指针找到页3.
2.将29和页3中的数据进行比较。26和30发现29依然存在于这个区间,那么继续使用页3中的p2的指针找到页8.
3.将29和页8的数据进行比较,可以得到匹配的key(29)从而读取对用的data。
B+Tree
B+树就是B树的一个升级。首先咱们看B+树的结构。

首先分析B+树和B树的区别:
1.B+树上除叶子节点其他节点是不存储数据的。B树上每个节点都存储了key和data。而B+树只在叶子节点上存储数据,其他节点只存储key。
为什么要进行这样的改变呢?
以innoDB存储引擎来说,数据库中页的大小是固定的,每页的默认大小为16K。如果页不存储数据(data)就可以存储更多的key,那么就可以尽可能的减少树的高度。总结来说B+树相对于B树来说又矮又胖。这时候如果查询那么就会降低很多IO操作。
假定一个页16K可以存储1000个key。那么3层的B+树就可以存储100010001000=10亿条数据。而且根节点是常驻内存的,也就是说查询10亿条数据只需要进行2次IO操作。
2.B+树所有的数据都存储在叶子节点上并且是按照顺序排列的。那么使用B+树完成范围查找,排序查找,分组查找,去重查找就会很简单,效率也比较高。而B树就不可以。因为B树的数据是分散个各个节点上的。
3.B+树上每页之间是一个双向链表进行链接,叶子节点中的数据都是使用单向链表链接的。但是需要记得一点的是B树也可以加链表。
PS:InnoDB存储引擎中索引就是这样存储的。InnoDB中的聚集索引就是上面的结构。需要记住一点是MyISAM中依然使用的是B+树,结构是一样的,原理也是一样的,区别在于存储不是数据而是数据的文件地址。
聚集索引和非聚集索引
聚集索引(聚簇索引):如果数据库使用InnoDB存储引擎,那么表中的数据一定会有一个主键,如果用户不创建主键系统也会帮你创建一个隐式的主键。
之所以一定要有主键因为InnoDB把数据放在B+树上,而B+树上的key就是主键。如果以主键构建的B+树索引那么就称之为聚集索引。
非聚集索引:以主键以外的列作为key构建B+树索引就称之为非聚集索引
使用聚集索引查找
select * from user where id>=18 and id<40

核心思想:
根节点是常驻内存的,所有不需要进行IO操作
根据各节点找到对应的p,根据p的指针找到对应的下一级页。最终达到叶子节点。通过二分查找法定位到数据位置,通过单向链表或者当前页的数据,再通过双向链表获取下一页的数据,最终获取所有需要查询的数据。
使用非聚集索引查找

如果使用的是非聚集索引那么叶子节点存储的内容发生了改变。聚集索引存储的是数据,非聚集索引存储的是当前数据对应的主键。
具体查找流程如下:

核心思想:
定位为查询的数据以后只能得到索引对应的主键,那么需要根据主键进行回表查询(拿着主键去聚集索引中获取数据)。