寻找一个好用的数据集需要注意一下几点:
数据集不混乱,否则要花费大量时间来清理数据;
数据集不应包含太多行或列,否则会难以使用;
数据越干净越好,清理大型数据集可能非常耗时;
应该预设一个有趣的问题,而这个问题又可以用数据来回答
数据集发布平台
AI Studio数据集:开放数据集-百度AI Studio - 人工智能学习与实训社区
天池数据集:数据集-阿里系唯一对外开放数据分享平台
Papers With Code数据集:Machine Learning Datasets | Papers With Code
Kaggle 数据集:Find Open Datasets and Machine Learning Projects | Kaggle爱竞赛的盆友们应该很熟悉了,Kaggle上有各种有趣的数据集,拉面评级、篮球数据、甚至西雅图的宠物许可证。
Graviti Open Datasets:公开数据集下载,优质机器学习数据集,图像识别、NLP免费获取 | 格物钛,非结构化数据平台
Huggingface数据集:Hugging Face – The AI community building the future.
CLUE 数据集:https://www.cluebenchmarks.com/dataSet_search.html
UCI机器学习库:最古老的数据集源之一,是寻找有趣数据集的第一站。可以直接从UCI机器学习库下载,无需注册
VisualData:分好类的计算机视觉数据集
目前为止:天池、kaggle、uci是个人使用最多的平台
NLP自然语言处理数据集
通用NLP数据集
HotspotQA数据集:具有自然、多跳问题的问答数据集,具有支持事实的强大监督,以实现更易于解释的问答系统。
安然数据集:来自安然高级管理层的电子邮件数据。
亚马逊评论:包含18年来亚马逊上的大约3500万条评论,数据包括产品和用户信息,评级和文本审核。
Google Books Ngrams:Google Books中的一系列文字。
Blogger Corpus:收集了来自blogger.com的681,288篇博文,每篇博文至少包含200个常用英语单词。
维基百科链接数据:维基百科的全文,包含来自400多万篇文章的近19亿个单词,可以按段落、短语或段落本身的一部分进行搜索。
Gutenberg电子书列表:Gutenberg项目中带注释的电子书书单。
Hansards加拿大议会文本:来自第36届加拿大议会记录的130万组文本。
Jeopardy:来自问答节目Jeopardy的超过200,000个问题的归档。
英文垃圾短信收集:由5574条英文垃圾短信组成的数据集。
Yelp评论:Yelp,就是美国的“大众点评”,这是他们发布的一个开放数据集,包含超过500万条评论。
UCI的Spambase:一个大型垃圾邮件数据集,对垃圾邮件过滤非常有用。
文本情感分析Sentiment analysis
多域情绪分析数据集:一个稍老一点的数据集,用到了来自亚马逊的产品评论。
IMDB评论:用于二元情绪分类的数据集,不过也有点老、有点小,有大约25000个电影评论。
斯坦福情绪树库:带有情感注释的标准情绪数据集。
Sentiment140:一个流行的数据集,它使用160,000条预先删除表情符号的推文。
Twitter美国航空公司情绪:2015年2月美国航空公司的Twitter数据,分类为正面,负面和中性推文。
医疗NLP数据集
医疗NLP数据汇总集合1
https://github.com/lrs1353281004/Chinese_medical_NLP
中文评测数据集
1. Yidu-S4K:医渡云结构化4K数据集
2.瑞金医院糖尿病数据集
3.Yidu-N7K:医渡云标准化7K数据集
4.中文医学问答数据集
5.平安医疗科技疾病问答迁移学习比赛
6.天池新冠肺炎问句匹配比赛
7.中文医患问答对话数据
8.中文医学问答数据
9.CHIP2020各项评测已开放
10.医学数据挖掘与算法评测大赛
中文医学知识图谱
CMeKG
英文数据集
PubMedQA: A Dataset for Biomedical Research Question Answering
中文医疗领域语料
医学教材 培训考试
哈工大《大词林》开放75万核心实体词及相关概念、关系列表(包含中药/医院/生物 类别)
医学embedding
开源英文医学embedding
医疗NLP数据汇总集合2——医疗行业专业词汇语料
https://github.com/xtea/chinese_medical_words
说明 | 数量 | 文件 |
口腔科病历词汇 | 11,170 | stomatology.txt |
国际疾病分类ICD全库 | 54,304 | ICD.csv |
疾病诊断编码库ICD-10 | 12109 | ICD-code-10.csv |
医院固定资产词汇 | 471 | properties.txt |
药品名称词汇 | 37,308 | medicine.txt |
电子病历常见词汇 | 1985 | emr.txt |
医疗NLP数据汇总集合3
中文医学NLP公开资源整理:术语集/语料库/词向量/预训练模型/知识图谱/命名实体识别/QA/信息抽取/etc
https://github.com/GanjinZero/awesome_Chinese_medical_NLP
术语集/语料库
medical-news 中文医学新闻爬虫
medical-books 中文LaTex开源医学书籍
THUOCL 清华大学thunlp组医学词汇
ICD-10-CN ICD-10中文对应
OMAHA七巧板医学术语集样例数据
中文糖尿病标注数据集 包含实体标注和关系标注
词向量/预训练模型
ChineseEHRBert 中文电子病历预训练Bert;用Bert测试命名实体识别,问答模型,关系提取任务
分词
PKUSEG PKUSEG分词工具,模型支持选择医学
知识图谱 / 关系提取
cMeKG Chinese Medical Knowledge Graph
瑞金医院人工智能辅助构建知识图谱大赛 糖尿病相关的学术论文以及糖尿病临床指南的实体标注和抽取实体关系任务
OMAHA知识图谱(药品适应症) 开放医疗与健康联盟(Open Medical and Healthcare Alliance,OMAHA)构建的药品与药品适应证的知识图谱数据
医疗知识图谱数据 医疗知识图谱数据(ownthink)
病人事件图谱数据集 病人事件图谱是一种新的基于RDF的医疗观察性数据表示模型,可以清晰地表示临床检查、诊断、治疗等多种事件类型以及事件的时序关系。使用三家上海三甲医院的电子病历数据,构建了包括3个专科、173395个医疗事件、501335个事件时序关系以及与5313个知识库概念链接的医疗数据集。
中医医案知识图谱 从医案中抽取临床知识构建知识图谱,帮助用户了解中医特色疗法,以及疾病(如“慢性胃炎”)的临床表现、相关疗法、相关养生保健方法等
herbnet 面向中药研究,根据中药领域模型的特点,构建了一个包括中医疾病,方剂,中药, 中药化学成分,药理作用,中药实验,化学实验方法在内的中药本体。进而,基于本体实现了一系列数据库的集成,从而构建了一个中药知识图谱。
CHIP2020 中文医学文本实体关系抽取
命名实体识别
CCKS2017 面向中文电子病历的医疗实体识别及属性抽取数据集
CCKS2018 面向中文电子病历的医疗实体识别及属性抽取数据集
CCKS2019 数据下载 面向中文电子病历的医疗实体识别及属性抽取数据集
CHIP2020 中文医学文本命名实体识别
CHIP2020 中药说明书实体识别
QA
CCIR2019 CCIR 2019 基于电子病历的数据查询类问答
cMedQA 中文医学QA数据集
cMedQA2 中文医学QA数据集
CMID 中文医学QA意图理解数据集
KGQA 基于医药知识图谱的智能问答系统
chatbot-base-on-Knowledge-Graph 使用深度学习方法解析问题 知识图谱存储 查询知识点 基于医疗垂直领域的对话系统
中文医疗对话数据集 Chinese medical dialogue data 中文医疗对话数据集
webMedQA webMedQA
MedDialog The MedDialog dataset contains conversations (in Chinese) between doctors and patients. It has 1.1 million dialogues and 4 million utterances.
CHIP2020 中医文献问题生成
术语标准化
CHIP2019 临床术语标准化任务:医渡云标准化7K数据集
CHIP2020 临床术语标准化任务
相似句对判断
“公益AI之星”挑战赛-新冠疫情相似句对判定大赛 比赛整理近万条真实语境下疫情相关的肺炎、支原体肺炎、支气管炎、上呼吸道感染、肺结核、哮喘、胸膜炎、肺气肿、感冒、咳血等患者提问句对,要求选手通过自然语言处理技术识别相似的患者问题。
其他
CHIP2018 针对中文的真实患者健康咨询语料,进行问句意图匹配
CHIP2019 平安医疗科技疾病问答迁移学习比赛
医疗NLP数据汇总集合4——医学诊断数据集
https://github.com/Toyhom/Chinese-medical-dialogue-data
这个数据集的Data_数据中有6个文件夹分别是:
<Andriatria_男科> 94596个问答对
<IM_内科> 220606个问答对
<OAGD_妇产科> 183751个问答对
<Oncology_肿瘤科> 75553个问答对
<Pediatric_儿科> 101602个问答对
<Surgical_外科> 115991个问答对 总计 792099个问答对
每个文件夹下有一个csv文件,其中的数据格式为:
department | title | ask | answer |
心血管科 | 高血压患者能吃党参吗? | 我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗? | 高血压病人可以口服党参的。党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。感谢您的进行咨询,期望我的解释对你有所帮助。 |
消化科 | 哪家医院能治胃反流 | 烧心,打隔,咳嗽低烧,以有4年多 | 建议你用奥美拉唑同时,加用吗丁啉或莫沙必利或援生力维,另外还可以加用达喜片 |
医疗NLP数据汇总集合4——中文医学问答目的理解数据集
https://github.com/liutongyang/CMID
This dataset is used for Chinese medical QA intent understanding task.
Dataset format:
All the data is stored in a JSON file. There are 5 fields in the file. An example as follows:
-
- {
- "originalText": "间质性肺炎的症状?",
- "entities": [{"label_type": "疾病和诊断", "start_pos": 0, "end_pos": 5}],
- "seg_result": ["间质性肺炎", "的", "症状", "?"],
- "label_4class": ["病症"],
- "label_36class": ["临床表现"]
- }
医疗NLP数据汇总集合5——中国社区医疗问答数据
https://github.com/zhangsheng93/cMedQA
This is the dataset for Chinese community medical question answering. The dataset is in version 1.0 and is available for non-commercial research. We will update and expand the database from time to time. In order to protect the privacy, the data is anonymized and no personal information is included.
医疗NLP数据汇总集合6——新冠病毒语料库
https://github.com/lwgkzl/Covid19-NLP
COVID19 Language Resources: Datasets
医疗NLP数据汇总集合7
https://github.com/chentao1999/MedicalRelationExtraction
BioCreative V chemical-disease relation (CDR) corpus (in short, BC5CDR corpus) (13, 14, 16, 34): It consists of 1,500 PubMed articles with 4,409 annotated chemicals, 5,818 diseases, and 3,116 chemical-disease interactions. The relation task data is publicly available through BioCreative V at https://biocreative.bioinformatics.udel.edu/resources/corpora/biocreative-v-cdr-corpus/.
Traditional Chinese medicine (TCM) literature corpus (in short, TCM corpus) (32): The abstracts of all 106,150 papers published in the 114 most popular Chinese TCM journals between 2011 to 2016 are collected. 3024 herbs, 4957 formulae, 1126 syndromes, and 1650 diseases are found. 5 types of relations are annotated. The entire dataset is available online at http://arnetminer.org/TCMRelExtr.
The 2012 informatics for integrating biology and the bedside (i2b2) project temporal relations challenge corpus (in short, i2b2 temporal corpus) (29, 30): It contains 310 de-identified discharge summaries of more than 178,000 tokens, with annotations of clinically significant events, temporal expressions and temporal relations in clinical narratives. On average, each discharge summary in the corpus contains 86.6 events, 12.4 temporal expressions, and 176 raw temporal relations. In this corpus, 8 kinds of temporal relations between events and temporal expressions are defined: BEFORE, AFTER, SIMULTANEOUS, OVERLAP, BEGUN_BY, ENDED_BY, DURING, BEFORE_OVERLAP. The entire annotations are available at http://i2b2.org/NLP/DataSets.
CV计算机视觉数据库
1.常用CV数据库
(1)MNIST
MNIST数据集大家可以说是耳熟能详。深度学习领域的“Hello World!”,入门必备!作为领域内最早的一个大型数据集,MNIST数据集包括60000个示例的训练集以及10000个示例的测试集,每个手写数字的大小均为28*28。此数据集是以二进制存储的,不能直接以图像格式查看,不过很容易找到将其转换成图像格式的工具。当前主流深度学习框架几乎无一例外将MNIST数据集的处理作为介绍及入门第一教程。
MNIST数据集官网地址:
http://yann.lecun.com/exdb/mnist/
数据集大小:~12MB
可视化展示0-9十个数字:

(2)Fashion MNIST
但大部分模型在MNIST上的分类精度都超过了95%。为了更直观地观察算法之间的差异,我们将使用一个图像内容更加复杂的数据集Fashion-MNIST。Fashion MNIST包含了10种类别70000个不同时尚穿戴品的图像,整体数据结构上跟MNIST完全一致。每张图像的尺寸同样是28*28。
Fashion MNIST数据集地址:
https://research.zalando.com/welcome/mission/research-projects/fashion-mnist/
可视化展示10种类别:

(3)CIFAR-10
相较于MNIST和Fashion MNIST的灰度图像,CIFAR-10数据集由10个类的60000个32*32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。
CIFAR-10是由Hinton的学生Alex Krizhevsky(AlexNet的作者)和Ilya Sutskever 整理的一个用于识别普适物体的彩色图像数据集。一共包含10个类别的RGB彩色图片:飞机( airplane)、汽车(automobile)、鸟类(bird)、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck)。
CIFAR-10的官方地址如下:
https://www.cs.toronto.edu/~kriz/cifar.html
CIFAR-10的可视化展示如下:

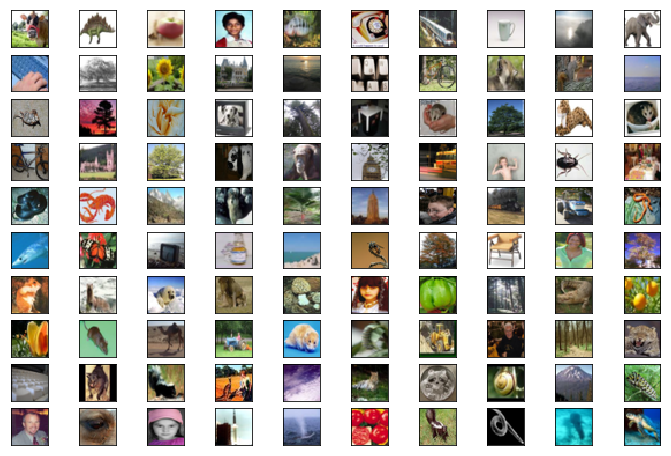
(4)CIFAR-100
CIFAR-100可以看作是CIFAR-10的扩大版,CIFAR-100将类别扩大到100个类,每个类包含了600张图像,分别有500张训练图像和100张测试图像。CIFAR-100的100个类被分为20个大类,每个大类又有一定数量的小类,大类和大类之间区分度较高,但小类之间有些图像具有较高的相似度,这对于分类模型来说会更具挑战性。CIFAR对于图像分类算法测试来说是一个非常不错的中小规模数据集。
CIFAR-100数据集地址:
https://www.cs.toronto.edu/~kriz/cifar.html
数据集大小:~170MB
CIFAR-100的可视化展示如下:
(5)ImageNet
MNIST将初学者领进了深度学习领域,而Imagenet数据集对深度学习的浪潮起了巨大的推动作用。深度学习领域大牛李飞飞在CVPR2009上发表了一篇名为《ImageNet: A Large-Scale Hierarchical Image Database》的论文在计算机视觉领域带来了一场“革命”,之后从2010年开始基于ImageNet数据集的7届ILSVRC大赛,这使得ImageNet极大的推动了深度学习和计算机视觉的发展。
Imagenet数据集是目前深度学习图像领域应用得非常多的一个领域,关于图像分类、定位、检测等研究工作大多基于此数据集展开。在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。
Imagenet数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注,具体信息如下:
1)Total number of non-empty synsets: 21841
2)Total number of images: 14,197,122
3)Number of images with bounding box annotations: 1,034,908
4)Number of synsets with SIFT features: 1000
5)Number of images with SIFT features: 1.2 million
数据官网地址为:
http://www.image-net.org/
数据集大小:~1TB(ILSVRC2016比赛全部数据)
ImageNet数据集示例:

(6)PASCAL VOC
PASCAL VOC挑战赛(The PASCAL Visual Object Classes)是一个世界级的计算机视觉挑战赛, 是视觉对象的分类识别和检测的一个基准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。PASCAL VOC图片集包括20个目录:人类;动物(鸟、猫、牛、狗、马、羊);交通工具(飞机、自行车、船、公共汽车、小轿车、摩托车、火车);室内(瓶子、椅子、餐桌、盆栽植物、沙发、电视)。数据集图像质量好,标注完备,非常适合用来测试算法性能。
目前PASCAL VOC主要分为VOC2007和VOC2012两个版本的数据集。VOC2007和
VOC2012的数据统计对比:

VOC数据集示例:
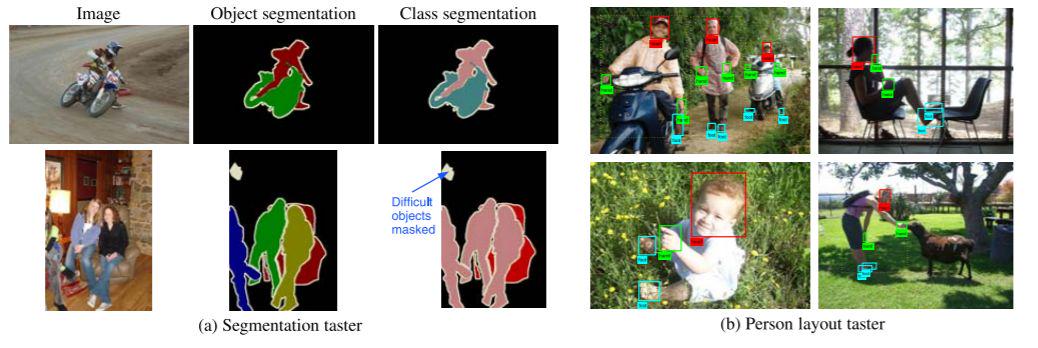
PASCAL VOC 数据集地址:
http://host.robots.ox.ac.uk/pascal/VOC/
数据集大小:~2GB
(7)COCO
COCO数据集是微软在ImageNet和PASCAL VOC数据集标注上的基础上产生的,主要是用于图像分类、检测和分割等任务。COCO全称为Common Objects in Context,其对于图像的标注信息不仅有类别、位置信息,还有对图像的语义文本描述COCO数据集的开源使得近两三年来图像分割语义理解取得了巨大的进展,也几乎成为了图像语义理解算法性能评价的“标准”数据集。
它有如下特点:
1)Object segmentation
2)Recognition in Context
3)Multiple objects per image
4)More than 300,000 images
5)More than 2 Million instances
6)80 object categories
7)5 captions per image
8)Keypoints on 100,000 people
COCO数据集主页地址:
http://cocodataset.org/#home
数据集大小:~40GB
COCO数据集示例:

2.自动驾驶数据集
Berkeley DeepDrive BDD100k:目前最大的自动驾驶数据集,包含超过100,000个视频,其中包括一天中不同时段和天气条件下超过1,100小时的驾驶体验。其中带注释的图像来自纽约和旧金山地区。
百度Apolloscapes:度娘的大型数据集,定义了26种不同物体,如汽车、自行车、行人、建筑物、路灯等。
Comma.ai:超过7小时的高速公路驾驶,细节包括汽车的速度、加速度、转向角和GPS坐标。
牛津的机器人汽车:这个数据集来自牛津的机器人汽车,它于一年时间内在英国牛津的同一条路上,反反复复跑了超过100次,捕捉了天气、交通和行人的不同组合,以及建筑和道路工程等长期变化。
城市景观数据集:一个大型数据集,记录50个不同城市的城市街景。
CSSAD数据集:此数据集对于自动驾驶车辆的感知和导航非常有用。不过,数据集严重偏向发达国家的道路。
KUL比利时交通标志数据集:来自比利时法兰德斯地区数以千计的实体交通标志的超过10000条注释。
MIT AGE Lab:在AgeLab收集的1,000多小时多传感器驾驶数据集的样本。
LISA:UC圣迭戈智能和安全汽车实验室的数据集,包括交通标志、车辆检测、交通信号灯和轨迹模式。
博世小交通灯数据集:用于深度学习的小型交通灯的数据集。
LaRa交通灯识别:巴黎的交通信号灯数据集。
WPI数据集:交通灯、行人和车道检测的数据集。
3. 医疗医学影像数据集
肺结节数据库LIDC-IDRI:LIDC-IDRI - The Cancer Imaging Archive (TCIA) Public Access - Cancer Imaging Archive Wiki
乳腺图像数据库DDSM MIAS:http://deckard.mc.duke.edu/ddsm_sql/book1.html
医学图像问答:Medical Image Format FAQ
ISBI:Challenges - Grand Challenge
github:https://github.com/linhandev/dataset
MIMIC-III:MIT计算生理学实验室的公开数据集,标记了约40000名重症监护患者的健康数据,包括人口统计学、生命体征、实验室测试、药物等维度。
4.其他CV数据集
Labelme:带注释的大型图像数据集。
ImageNet:大家熟悉的ImageNet,女神李飞飞参与创建,同名比赛影响整个计算机视觉界。
LSUN:场景理解与许多辅助任务(房间布局估计,显着性预测等)
MS COCO:同样也是知名计算机视觉数据集,同名比赛每年都被中国人屠榜。
COIL 100:100个不同的物体在360度旋转的每个角度成像。
视觉基因组:非常详细的视觉知识库。
谷歌开放图像:在知识共享下的900万个图像网址集合“已经注释了超过6000个类别的标签”。
野外标记面:13000张人脸标记图像,可以用于开发涉及面部识别的应用程序。
斯坦福狗子数据集:20580张狗子的图片,包括120个不同品种。
室内场景识别:包含67个室内类别,15620个图像。
KITTI数据集:The KITTI Vision Benchmark Suite (cvlibs.net)
Cityscapes:Cityscapes Dataset – Semantic Understanding of Urban Street Scenes (cityscapes-dataset.com)
牛津数据集:Datasets (ox.ac.uk)
ApolloScape:Apollo Scape
BDD100K:Berkeley DeepDrive
Waymo Open Dataset:GitHub - waymo-research/waymo-open-dataset: Waymo Open Dataset
nuScenes数据集:https://www.nuscenes.org/download
3D Photography Dataset:(uiuc.edu)
Matterport 3D重建数据集:Capture, share, and collaborate the built world in immersive 3D (matterport.com)
NoW Dataset:(mpg.de)
Pix3D:Pix3D (mit.edu)
Replica Dataset:GitHub - facebookresearch/Replica-Dataset: The Replica Dataset v1 as published in https://arxiv.org/abs/1906.05797 .
Scan2CAD:[GitHub - skanti/Scan2CAD: CVPR'19] Dataset and code used in the research project Scan2CAD: Learning CAD Model Alignment in RGB-D Scans
ScanNet:ScanNet | Richly-annotated 3D Reconstructions of Indoor Scenes (scan-net.org)
NYC3Dcars:NYC3DCars (cornell.edu)
Expressive Hands and Faces:Computer Vision Group - Home (tum.de)
TUM数据集:SMPL-X (mpg.de)
EUROC数据集:[kmavvisualinertialdatasets – ASL Datasets (ethz.ch)
公共政府数据集
Data.gov:该网站可以从多个美国政府机构下载数据,包括各种奇怪的数据,从政府预算到考试分数都有。不过,其中大部分数据需要进一步研究。
食物环境地图集:本地食材如何影响美国饮食的数据。
学校财务系统:美国学校财务系统的调查。
慢性病数据:美国各地区慢性病指标数据。
美国国家教育统计中心:教育机构和教育人口统计数据,不仅有美国的数据,也有一些世界上其他地方的数据。
英国数据服务:英国最大的社会、经济和人口数据集。
数据美国:全面可视化的美国公共数据。
中国国家统计局:http://www.stats.gov.cn/