
>>>深度学习Tricks,第一时间送达<<<
目录
RepVGG——极简架构,SOTA性能!!!
(一)前沿介绍
1.RepVGGBlock模块
2.相关实验结果
(二)YOLOv5/YOLOv7改进之结合RepVGG
1.配置common.py文件
2.配置yolo.py文件
3.配置yolov5/yolov7_RepVGG.yaml文件
RepVGG——极简架构,SOTA性能!!!
(一)前沿介绍
论文题目:RepVGG: Making VGG-style ConvNets Great Again
论文地址:https://arxiv.org/abs/2101.03697
代码地址:https://github.com/DingXiaoH/RepVGG
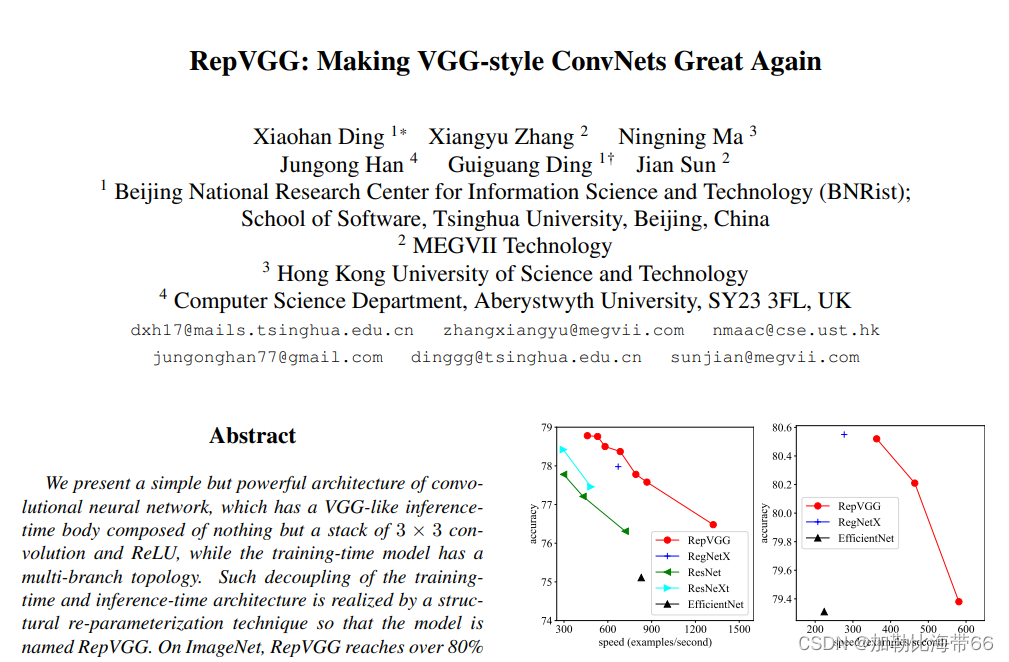
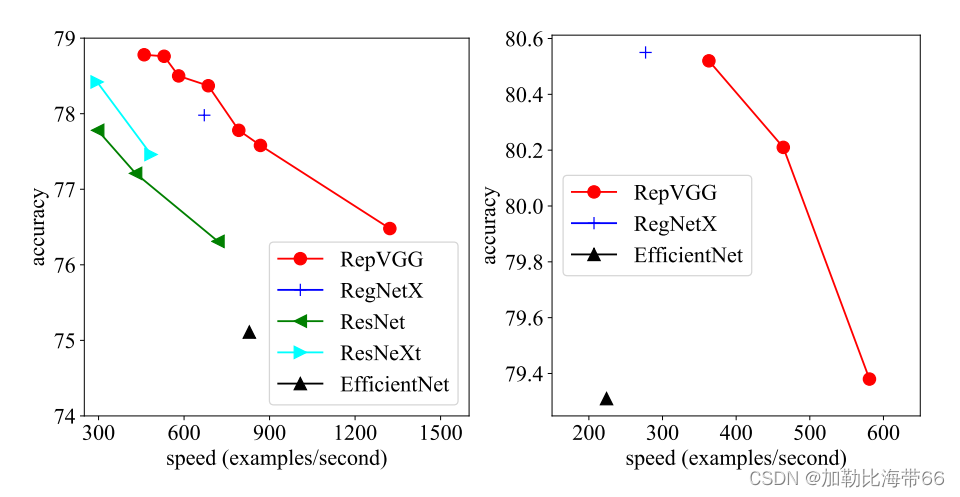
作者提出了一个简单但功能强大的卷积神经网络架构,该架构推理时候具有类似于VGG的骨干结构,该主体仅由3 x 3卷积和ReLU堆叠组成,而训练时候模型采用多分支拓扑结构。 训练和推理架构的这种解耦是通过结构重参数化技术实现的,因此该模型称为RepVGG。 在ImageNet上,据我们所知,RepVGG的top-1准确性达到80%以上,这是老模型首次实现该精度。 在NVIDIA 1080Ti GPU上,RepVGG模型的运行速度比ResNet-50快83%,比ResNet-101快101%,并且具有更高的精度,与诸如EfficientNet和RegNet的最新模型相比,RepVGG显示出良好的精度-速度权衡。效果对比如下图所示。
该论文主要有以下三点贡献:
1.更快
除了Winograd conv带来的加速之外,FLOPs和速度之间的差异可以归因于两个重要因素,它们对速度有很大影响,但FLOPs并未考虑这些因素:内存访问成本(MAC)和并行度。 另一方面,在相同的FLOPs下,具有高并行度的模型可能比具有低并行度的模型快得多。因此简单的推理结构可以避免多分支的零碎计算。
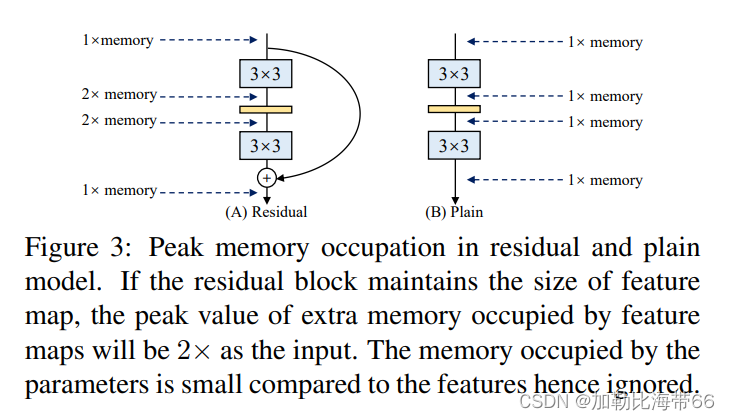
2.更省内存
如图(A)所示的Residual模块,假设卷积层不改变channel的数量,那么在主分支和shortcut分支上都要保存各自的特征图或者称Activation,那么在add操作前占用的内存大概是输入Activation的两倍,而图(B)的Plain结构占用内存始终不变。
VGG是一个直筒性单路结构,由上述分析可知,单路结构会占有更少的内存,因为不需要保存其中间结果,同时,单路架构非常快,因为并行度高。同样的计算量,大而整的运算效率远超小而碎的运算。
3.更加灵活
作者在论文中提到了模型优化的剪枝问题,对于多分支的模型,结构限制较多剪枝很麻烦,而对于Plain结构的模型就相对灵活很多,剪枝也更加方便。
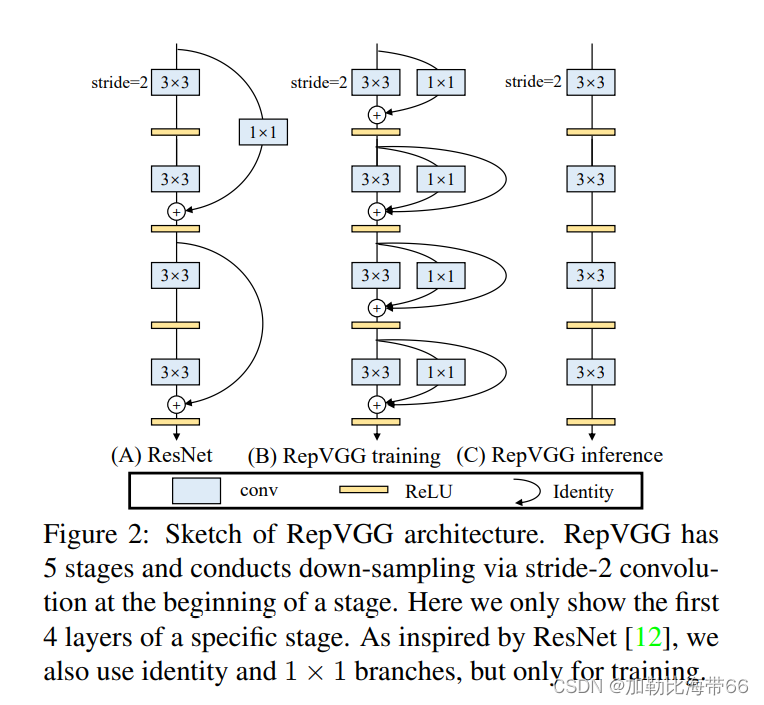
1.RepVGGBlock模块
2.相关实验结果
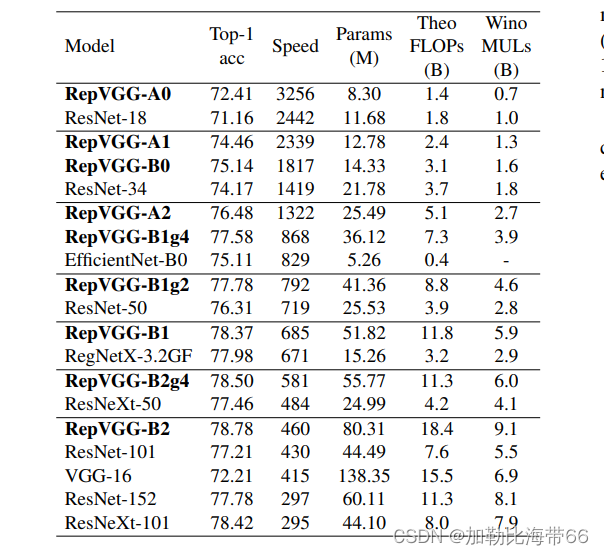
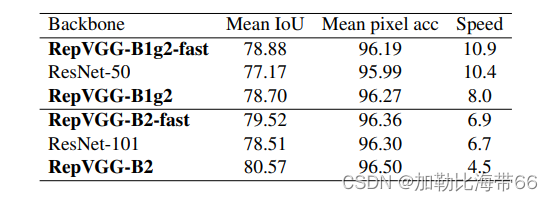
(二)YOLOv5/YOLOv7改进之结合RepVGG
改进方法和其他模块一样,分三步走:
1.配置common.py文件
- #RepVGGBlock
- class RepVGGBlock(nn.Module):
-
- def __init__(self, in_channels, out_channels, kernel_size=3,
- stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
- super(RepVGGBlock, self).__init__()
- self.deploy = deploy
- self.groups = groups
- self.in_channels = in_channels
-
- padding_11 = padding - kernel_size // 2
-
- self.nonlinearity = nn.SiLU()
-
- # self.nonlinearity = nn.ReLU()
-
- if use_se:
- self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
- else:
- self.se = nn.Identity()
-
- if deploy:
- self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
- stride=stride,
- padding=padding, dilation=dilation, groups=groups, bias=True,
- padding_mode=padding_mode)
-
- else:
- self.rbr_identity = nn.BatchNorm2d(
- num_features=in_channels) if out_channels == in_channels and stride == 1 else None
- self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
- stride=stride, padding=padding, groups=groups)
- self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
- padding=padding_11, groups=groups)
- # print('RepVGG Block, identity = ', self.rbr_identity)
-
- def get_equivalent_kernel_bias(self):
- kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
- kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
- kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
- return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
-
- def _pad_1x1_to_3x3_tensor(self, kernel1x1):
- if kernel1x1 is None:
- return 0
- else:
- return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
-
- def _fuse_bn_tensor(self, branch):
- if branch is None:
- return 0, 0
- if isinstance(branch, nn.Sequential):
- kernel = branch.conv.weight
- running_mean = branch.bn.running_mean
- running_var = branch.bn.running_var
- gamma = branch.bn.weight
- beta = branch.bn.bias
- eps = branch.bn.eps
- else:
- assert isinstance(branch, nn.BatchNorm2d)
- if not hasattr(self, 'id_tensor'):
- input_dim = self.in_channels // self.groups
- kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
- for i in range(self.in_channels):
- kernel_value[i, i % input_dim, 1, 1] = 1
- self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
- kernel = self.id_tensor
- running_mean = branch.running_mean
- running_var = branch.running_var
- gamma = branch.weight
- beta = branch.bias
- eps = branch.eps
- std = (running_var + eps).sqrt()
- t = (gamma / std).reshape(-1, 1, 1, 1)
- return kernel * t, beta - running_mean * gamma / std
-
- def forward(self, inputs):
- if hasattr(self, 'rbr_reparam'):
- return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
-
- if self.rbr_identity is None:
- id_out = 0
- else:
- id_out = self.rbr_identity(inputs)
-
- return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
-
- def fusevggforward(self, x):
- return self.nonlinearity(self.rbr_dense(x))
2.配置yolo.py文件
加入RepVGGBlock模块。

3.配置yolov5/yolov7_RepVGG.yaml文件
- # anchors
- anchors:
- - [10,13, 16,30, 33,23] # P3/8
- - [30,61, 62,45, 59,119] # P4/16
- - [116,90, 156,198, 373,326] # P5/32
-
- # YOLOv5 backbone
- backbone:
- # [from, number, module, args]
- [[-1, 1, RepVGGBlock, [64, 3, 2]], # 0-P1/2
- [-1, 1, RepVGGBlock, [64, 3, 2]], # 1-P2/4
- [-1, 1, RepVGGBlock, [64, 3, 1]], # 2-P2/4
- [-1, 1, RepVGGBlock, [128, 3, 2]], # 3-P3/8
- [-1, 3, RepVGGBlock, [128, 3, 1]],
- [-1, 1, RepVGGBlock, [256, 3, 2]], # 5-P4/16
- [-1, 13, RepVGGBlock, [256, 3, 1]],
- [-1, 1, RepVGGBlock, [512, 3, 2]], # 7-P4/16
- ]
- # YOLOv5 head
- head:
- [[-1, 1, Conv, [256, 1, 1]],
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 6], 1, Concat, [1]], # cat backbone P4
- [-1, 1, C3, [256, False]], # 11
-
- [-1, 1, Conv, [128, 1, 1]],
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 4], 1, Concat, [1]], # cat backbone P3
- [-1, 1, C3, [128, False]], # 15 (P3/8-small)
-
- [-1, 1, Conv, [128, 3, 2]],
- [[-1, 12], 1, Concat, [1]], # cat head P4
- [-1, 1, C3, [256, False]], # 18 (P4/16-medium)
-
- [-1, 1, Conv, [256, 3, 2]],
- [[-1, 8], 1, Concat, [1]], # cat head P5
- [-1, 1, C3, [512, False]], # 21 (P5/32-large)
-
- [[15, 18, 21], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
- ]


