作者 | 张闻阗
前言
2022 年 3 月 15 日,Google 发布了万众瞩目的 Golang 1.18,带来了好几个重大的新特性,包括:
- 解决本地同时开发多个仓库带来的一些问题的工作区(Workspace)
- 能够自动探测代码分支,随机生成输入,并且检查代码是否会 panic 的模糊测试(Fuzzing Test)
- 众多开发者盼星星盼月亮终于等到的泛型支持。
本文将简单讲述这三个特性的相关内容。
Go 工作区模式(Go Workspace Mode)
现实的情况
多仓库同时开发
在实际的开发工作中,我们经常会同时修改存在依赖关系的多个 module,例如在某个 service 模块上实现需求的同时,也需要对项目组的某个 common 模块做出修改,整个的工作流就会变成下面这样:
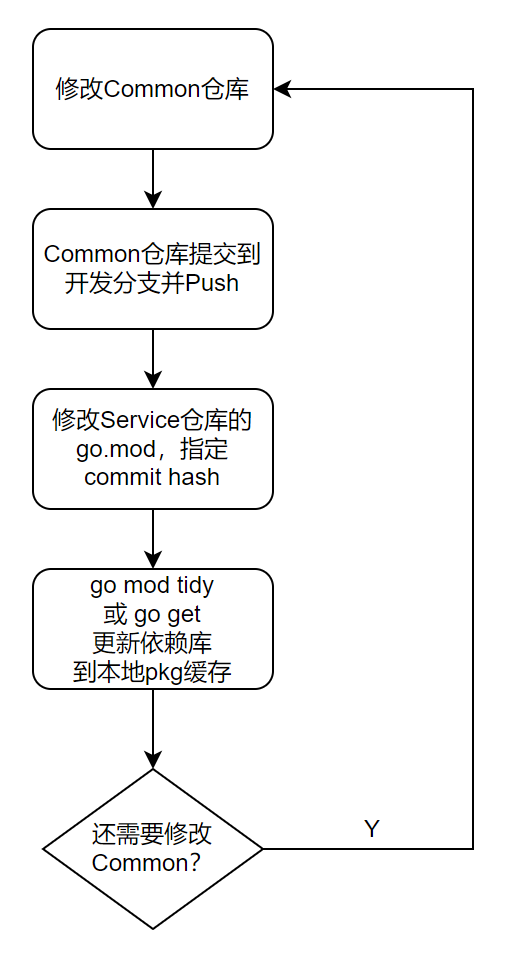
可以看到,每次修改 Common 库,都需要将代码 push 到远端,然后再修改本地 service 仓库的依赖,再通过 go mod tidy 从远端拉取 Common 代码,不可谓不麻烦。
有些同学可能会问了,这种情况,在 service 仓库的 go.mod 中添加一条 replace 不就能够解决吗?
但是,如果在 go.mod 中使用 replace,在维护上需要付出额外的心智成本,万一将带有 replace 的 go.mod 推到远端代码库了,其他同学不就一脸懵逼了?
多个新仓库开始开发
假设此时我正在开发两个新的模块,分别是:
code.byted.org/SomeNewProject/Common
code.byted.org/SomeNewProject/MyService- 1.
- 2.
并且 MyService 依赖于 Common。
在开发过程中,出于各种原因,有可能不会立即将代码推送到远端,那么此时假设我需要本地编译 MyService,就会出现 go build(或者 go mod tidy)自动下载依赖失败,因为此时 Common 库根本就没有发布到代码库中。
出于和上述“多仓库同时开发”相同的理由,replace 也不应该被添加到 MyService 的 go.mod 文件中。
工作区模式是什么
Go 工作区模式最早出现于 Go 开发者 Michael Matloob 在 2021 年 4 月提出的一个名为“Multi-Module Workspaces in cmd/go”的提案。
这个提案中提出,新增一个 go.work 文件,并且在这个文件中指定一系列的本地路径,这些本地路径下的 go module 共同构成一个工作区(workspace),go 命令可以操作这些路径下的 go module,在编译时也会优先使用这些 go module。
使用如下命令就可以初始化一个工作区,并且生成一个空的 go.work 文件:
go work init .- 1.
新生成的 go.work 文件内容如下:
go 1.18
directory ./.- 1.
- 2.
go.work 文件中,directory 指示了工作区的各个 module 目录,在编译代码时,会优先使用同一个 workspace 下的 module。
在 go.work 中,也支持使用 replace 来指定使用本地代码库,但在大多数情况下,更好的做法是将依赖的本地代码库的路径加入 directory 中。
推荐的使用方法
因为 go.work 描述的是本地的工作区,所以也是不能提交到远端代码库的,虽然可以在.gitignore 中加入这个文件,但是最推荐的做法还是在本地代码库的上层目录使用 go.work。
例如上述的“多个新仓库开始开发”的例子,假设我的两个仓库的本地路径分别是:
/Users/bytedance/dev/my_new_project/common
/Users/bytedance/dev/my_new_project/my_service- 1.
- 2.
那么我就可以在“/Users/bytedance/dev/my_new_project”目录下生成一个如下内容的 go.work:
/Users/bytedance/dev/my_new_project/go.work:
go 1.18
directory (
./common
./my_service
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
在上层目录放置 go.work,也可以将多个目录组织成一个 workspace,并且由于上层目录本身不受 git 管理,所以也不用去管 gitignore 之类的问题,是比较省心的方式。
使用时的注意点
目前(go 1.18)仅 go build 会对 go.work 做出判断,而 go mod tidy 并不 care Go 工作区。
Go 模糊测试(Go Fuzzing Test)
为什么 Golang 要支持模糊测试
从 1.18 起,模糊测试(Fuzzing Test)作为语言安全的一环,加入了 Golang 的 testing 标准库。Golang 加入模糊测试的原因非常明显:安全是程序员在构建软件的过程中必不可少且日益重要的考量因素。
Golang 至今为止,已经在保障语言安全方面提供了很多的特性和工具,例如强制使用显式类型转换、禁止隐式类型转换、对数组与切片的越界访问检查、通过 go.sum 对依赖包进行哈希校验等等。
在进入云原生时代之后,Golang 成为了云原生基础设施与服务的头部语言之一。这些系统对安全性的要求自然不言而喻。尤其是针对用户的输入,不被用户的输入弄出处理异常、崩溃、被操控是对这些系统的基本要求之一。
这就要求我们的系统在处理任何用户输入的时候都能保持稳定,但是传统的质量保障手段,例如 Code Review、静态分析、人工测试、Unit Test 等等,在面对日益复杂的系统时,自然就无法穷尽所有可能的输入组合,尤其是一些非常不明显的 corner case。
而模糊测试就是业界在解决这方面问题的优秀实践之一,Golang 选择支持它也就不难理解了。
模糊测试是什么
模糊测试是一种通过数据构造引擎,辅以开发者可以提供的一些初始数据,自动构造出一些随机数据,作为对程序的输入来进行测试的一种方式。模糊测试可以帮助开发人员发现难以发现的稳定性、逻辑性甚至是安全性方面的错误,特别是当被测系统变得更加复杂时。
模糊测试在具体的实现上,通常可以不依赖于开发测试人员定义好的数据集,取而代之的则是一组通过数据构造引擎自行构造的一系列随机数据。模糊测试会将这些数据作为输入提供给待测程序,并且监测程序是否出现 panic、断言失败、无限循环,或者其他什么异常情况。这些通过数据构造引擎生成的数据被称为语料(corpus)。另外模糊测试其实也是一种持续测试的手段,因为如果不限制执行的次数或者执行的最大时间,它就会一直不停的执行下去。
Golang 的模糊测试由于被实现在了编译器工具链中,所以采用了一种名为“覆盖率引导的 fuzzing”的入参生成技术,大致运行过程如下:

Golang 的模糊测试如何使用
Golang 的模糊测试在使用时,可以简单地直接使用,也可以自己提供一些初始的语料。
最简单的实践例子
模糊测试的函数也是放在 xxx_test.go 里的,编写一个最简单的模糊测试例子(明显的除 0 错误):
package main
import "testing"
import "fmt"
func FuzzDiv(f *testing.F) {
f.Fuzz(func(t *testing.T, a, b int) {
fmt.Println(a/b)
})
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
可以看到类似于单元测试,模糊测试的函数名都是 FuzzXxx 格式,且接受一个 testing.F 指针对象。
然后在函数中使用 f.Fuzz 对指定的函数进行模糊测试,被测试的函数的第一个参数必须是“*testing.T”类型,后面可以跟任意多个基本类型的参数。
编写完成之后,使用这样的命令来启动模糊测试:
go test -fuzz .- 1.
模糊测试默认会一直进行下去,只要被测试的函数不 panic 不出错。可以通过“-fuzztime”选项来限制模糊测试的时间:
go test -fuzztime 10s -fuzz .- 1.
使用模糊测试对上述代码进行测试时,会碰到产生 panic 的情况,此时模糊测试会输出如下信息:
warning: starting with empty corpus
fuzz: elapsed: 0s, execs: 0 (0/sec), new interesting: 0 (total: 0)
fuzz: elapsed: 0s, execs: 1 (65/sec), new interesting: 0 (total: 0)
--- FAIL: FuzzDiv (0.02s)
--- FAIL: FuzzDiv (0.00s)
testing.go:1349: panic: runtime error: integer divide by zero
goroutine 11 [running]:
runtime/debug.Stack()
/Users/bytedance/.mytools/go/src/runtime/debug/stack.go:24 +0x90
testing.tRunner.func1()
/Users/bytedance/.mytools/go/src/testing/testing.go:1349 +0x1f2
panic({0x1196b80, 0x12e3140})
/Users/bytedance/.mytools/go/src/runtime/panic.go:838 +0x207
mydev/fuzz.FuzzDiv.func1(0x0?, 0x0?, 0x0?)
/Users/bytedance/Documents/dev_test/fuzz/main_test.go:8 +0x8c
reflect.Value.call({0x11932a0?, 0x11cbf68?, 0x13?}, {0x11be123, 0x4}, {0xc000010420, 0x3, 0x4?})
/Users/bytedance/.mytools/go/src/reflect/value.go:556 +0x845
reflect.Value.Call({0x11932a0?, 0x11cbf68?, 0x514?}, {0xc000010420, 0x3, 0x4})
/Users/bytedance/.mytools/go/src/reflect/value.go:339 +0xbf
testing.(*F).Fuzz.func1.1(0x0?)
/Users/bytedance/.mytools/go/src/testing/fuzz.go:337 +0x231
testing.tRunner(0xc000003a00, 0xc00007e3f0)
/Users/bytedance/.mytools/go/src/testing/testing.go:1439 +0x102
created by testing.(*F).Fuzz.func1
/Users/bytedance/.mytools/go/src/testing/fuzz.go:324 +0x5b8
Failing input written to testdata/fuzz/FuzzDiv/2058e4e611665fa289e5c0098bad841a6785bf79d30e47b96d8abcb0745a061c
To re-run:
go test -run=FuzzDiv/2058e4e611665fa289e5c0098bad841a6785bf79d30e47b96d8abcb0745a061c
FAIL
exit status 1
FAIL mydev/fuzz 0.059s- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
其中的:
Failing input written to testdata/fuzz/FuzzDiv/2058e4e611665fa289e5c0098bad841a6785bf79d30e47b96d8abcb0745a061c- 1.
这一行表示模糊测试将出现 panic 的测试入参保存到了这个文件里面,此时尝试输出这个文件的内容:
go test fuzz v1
int(-60)
int(0)- 1.
- 2.
- 3.
就可以看到引发 panic 的入参,此时我们就可以根据入参检查我们的代码是哪里有问题。当然,这个简单的例子就是故意写了个除 0 错误。
提供自定义语料
Golang 的模糊测试还允许开发者自行提供初始语料,初始语料可以通过“f.Add”方法提供,也可以将语料以上面的“Failing input”相同的格式,写入“testdata/fuzz/FuzzXXX/自定义语料文件名”中。
使用时的注意点
目前 Golang 的模糊测试仅支持被测试的函数使用这些类型的参数:
[]byte, string, bool, byte, rune, float32, float64,
int, int8, int16, int32, int64, uint, uint8, uint16, uint32, uint64- 1.
- 2.
根据标准库的文档描述,更多的类型支持会在以后加入。
Go 的泛型
Golang 在 1.18 中终于加入了对泛型的支持,有了泛型之后,我们可以这样写一些公共库的代码:
旧代码(反射):
func IsContainCommon(val interface{}, array interface{}) bool {
switch reflect.TypeOf(array).Kind() {
case reflect.Slice:
lst := reflect.ValueOf(array)
for index := 0; index < lst.Len(); index++ {
if reflect.DeepEqual(val, lst.Index(index).Interface()) {
return true
}
}
}
return false
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
新代码(泛型):
func IsContainCommon[T any](val T, array []T) bool {
for _, item := range array {
if reflect.DeepEqual(val, item) {
return true
}
}
return false
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
泛型在 Golang 中增加了三个新的重要特性:
- 在定义函数和类型时,支持使用类型参数(Type parameters)
- 将接口(interface)重新定义为“类型的集合”
- 泛型支持类型推导
下面逐个对这些内容进行简单说明。
类型参数(Type Parameters)
现在在定义函数和类型时,支持使用“类型参数”,类型参数的列表和函数参数列表很相似,只不过它使用的是方括号:
func Min[T constraints.Ordered](x, y T) T {
if x < y {
return x
}
return y
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
上述的代码中,给 Min 函数定义了一个参数类型 T,这很类似于 C++中的“template < typename T > ”,只不过在 Golang 中,可以为这种参数类型指定它需要满足的“约束”。在这个例子中,使用的“约束”是“constraints.Ordered”。
然后就可以按照如下方式,使用这个函数了:
x := Min[int](1, 2)
y := Min[float64](1.1, 2.2)- 1.
- 2.
为泛型函数指定类型参数的过程叫做“实例化(Instantiation)”,也可以将实例化后的函数保存成为函数对象,并且进一步使用:
f := Min[int64] // 这一步保存了一个实例化的函数对象
n := f(123, 456)- 1.
- 2.
同样的,自定义的类型也支持泛型:
type TreeNode[T interface{}] struct {
left, right *TreeNode[T]
value T
}
func (t *TreeNode[T]) Find(x T) { ... }
var myBinaryTree TreeNode[int]- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
如上述代码,struct 类型在使用泛型时,支持自己的成员变量和自己持有同样的泛型类型。
类型集合(Type Sets)
下面稍微深入的讲一下上述例子提到的“约束”。上文的例子中的“int”“float64”“int64”在实例化时,实际上是被作为“参数”传递给了“类型参数列表”,即上文例子中的“[T constraints.Ordered]”。
就像传递普通参数需要校验参数的类型一样,传递类型参数时也需要对被传递的类型参数进行校验,检查被传递的类型是否满足要求。
例如上文例子中,使用“int”“float64”“int64”这几个类型对 Min 函数进行实例化时,编译器都会检查这些参数是否满足“constraints.Ordered”这个约束。而这个约束描述了所有可以使用“<”进行比较的类型的集合,这个约束本身也是一个 interface。
在 Go 的泛型中,类型约束必须是一种 interface,而“传统”的 Golang 中对 interface 的定义是“一个接口定义了一组方法集合”,任何实现了这组方法集合的类型都实现了这个 interface:

不过这里就出现了一个问题:“<”的比较显然不是一个方法(Go 当中不存在 C++的运算符重载),而描述了这个约束的 constraints.Ordered 自身的确也是一个 interface。
所以从 1.18 开始,Golang 将 Interface 重新定义为“一组类型的集合”,按照以前对 interface 的看法,也可以将一个 interface 看成是“所有实现了这个 interface 的方法集合的类型所构成的集合”:

其实两种看法殊途同归,但是后者显然可以更灵活,直接将一组具体类型指定成一个 interface,即使这些类型没有任何的方法。
例如在 1.18 中,可以这样定义一个 interface:
type MyInterface interface {
int|bool|string
}- 1.
- 2.
- 3.
这样的定义表示 int/bool/string 都可以被当作 MyInterface 进行使用。
那么回到 constraints.Ordered,它的定义实际上是:
type Ordered interface {
Integer|Float|~string
}
type Float interface {
~float32|~float64
}
type Integer interface {
Signed|Unsigned
}
type Signed interface {
~int|~int8|~int16|~int32|~int64
}
type Unsigned interface {
~uint|~uint8|~uint16|~uint32|~uint64
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
其中前置的“~”符号表示“任何底层类型是后面所跟着的类型的类型”,例如:
type MyString string- 1.
这样定义的 MyString 是可以满足“~string”的类型约束的。
类型推导(Type Inference)
最后,所有支持泛型的语言都会有的类型推导自然也不会缺席。类型推导功能可以允许使用者在调用泛型函数时,无需指定所有的类型参数。例如下面这个函数:
// 将F类型的slice变换为T类型的slice
// 关键字 any 等同于 interface{}
func Map[F, T any](src []F, f func(F) T) []T {
ret := make([]T, 0, len(src))
for _, item := range src {
ret = append(ret, f(item))
}
return ret
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
在使用时可以这样:
var myConv := func(i int)string {return fmt.Sprint(i)}
var src []int
var dest []string
dest = Map[int, string](src, myConv) // 明确指定F和T的类型
dest = Map[int](src, myConv) // 仅指定F的类型,T的类型交由编译器推导
dest = Map(src, myConv) // 完全不指定类型,F和T都交由编译器推导- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
泛型函数在使用时,可以不指定具体的类型参数,也可以仅指定类型参数列表左边的部分类型。当自动的类型推导失败时,编译器会报错。
Golang 泛型中的类型推导主要分为两大部分:
- 函数参数类型推导:通过函数的入参,对类型参数对应的具体类型进行推导。
- 约束类型推导:通过已知具体类型的类型参数,来推断出未知类型参数的具体类型。
而这两种类型推导,都依赖一种名为“类型统一化(Type Unification)”的技术。
类型统一化(Type Unification)
类型统一化是对两个类型进行比较,这两个类型有可能本身是一个类型参数,也有可能包含一个类型参数。
比较的过程是对这两个类型的“结构”进行对比,并且要求被比较的两个类型满足下列条件:
- 剔除类型参数后,两个类型的“结构”必须能够匹配
- 剔除类型参数后,结构中剩余的具体类型必须相同
- 如果两者均不含类型参数,那么两者的类型必须完全相同,或者底层数据类型完全相同
这里说的“结构”,指的是类型定义中的 slice、map、function 等等,以及它们之间的任意嵌套。
满足这几个条件时,类型统一性对比才算做成功,编译器才能进一步对类型参数进行推测,例如:
如果我们此时有“T1”、“T2”两个类型参数,那么“[]map[int]bool”可以匹配如下类型:
[]map[int]bool // 它本身
T1 // T1被推断为 []map[int]bool
[]T1 // T1被推断为 map[int]bool
[]map[T1]T2 // T1被推断为 int, T2被推断为 bool- 1.
- 2.
- 3.
- 4.

作为反例,“[]map[int]bool”显然无法匹配这些类型:
int
struct{}
[]struct{}
[]map[T1]string
// etc...- 1.
- 2.
- 3.
- 4.
- 5.
函数参数类型推导(Function Argument Type Inference)
函数参数类型推导,顾名思义是在泛型函数被调用时,如果没有被完全指定所有的类型参数,那么编译器就会根据函数实际入参的类型,对类型参数所对应的具体类型进行推导,例如本文最开始的 Min 函数:
func Min[T constraints.Ordered](x, y T) T {
if x < y {
return x
}
return y
}
ans := Min(1, 2) // 此时类型参数T被推导为int- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
和其他支持泛型的语言一样,Golang 的函数参数类型推导只支持“能够从入参推导的类型参数”,如果类型参数用于标记返回类型,那么在使用时必须明确指定类型参数:
func MyFunc[T1, T2, T3 any](x T1) T2 {
// ...
var x T3
// ...
}
ans := MyFunc[int, bool, string](123) // 需要手动指定- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
类似这样的函数,部分的类型参数仅出现在返回值当中(或者仅出现在函数体中,不作为入参或出参出现),就无法使用函数参数类型推导,而必须明确手动指定类型。
推导算法与示例

还是拿 Min 函数作为例子,讲解一下函数参数类型推导的过程:
func Min[T constraints.Ordered](x, y T) T {
if x < y {
return x
}
return y
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
先来看看第一种情况:
Min(1, 2)- 1.
此时两个入参均为无类型字面值常量,所以第一轮的类型统一化被跳过,且入参的具体类型没有被确定,此时编译器尝试使用两个参数的默认类型 int,由于两个入参在函数定义处的类型都是“T”,且两者都使用默认类型 int,所以此时 T 被成功推断为 int。
然后来看第二种情况:
Min(1, int64(2))- 1.
此时第二个参数有一个明确的类型 int64,所以在第一轮的类型统一化中,T 被推断为 int64,且在尝试为第一轮漏掉的第一个参数“1”确定类型时,由于“1”是一个合法的 int64 类型值,所以 T 被成功推断为 int64。
再来看第三种情况:
Min(1.5, int64(2))- 1.
此时第二个参数有一个明确的类型 int64,所以在第一轮的类型统一化中,T 被推断为 int64,且在尝试为第一轮漏掉的第一个参数“1.5”确定类型时,由于“1.5”不是一个合法的 int64 类型值,类型推导失败,此时编译器报错。
最后看第四种情况:
Min(1, 2.5)- 1.
和第一种情况类似,第一轮的类型统一化被跳过,且两个入参的具体类型没有被确定,此时编译器开始尝试使用默认类型。两个参数的默认类型分别是 int 和 float64,由于在类型推导中,同一个类型参数 T 只能被确定为一种类型,所以此时类型推导也会失败。
约束类型推导(Constraints Type Inference)
约束类型推导是 Golang 泛型的另一个强大武器,它可以允许编译器通过一个类型参数来推导另一个类型参数的具体类型,也可以通过使用类型参数来保存调用者的类型信息。
约束类型推导可以允许使用其他类型参数来为某个类型参数指定约束,这类约束被称为“结构化约束”,这种约束定义了类型参数必须满足的数据结构,例如:
// 将一个整数slice中的每个元素都x2后返回
func DoubleSlice[S ~[]E, E constraints.Integer](slice S) S {
ret := make(S, 0, len(slice))
for _, item := range slice {
ret = append(ret, item + item)
}
return ret
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
在这个函数的定义中,“~[]E”就是一个简写的对 S 的结构化约束,其完整写法应是“interface{~[]E}”,即以类型集合的方式来定义的 interface,且其中只包含一种定义“~[]E”,意为“底层数据类型是[]E 的所有类型”。
注意,一个合法的结构化约束所对应的类型集合,应该满足下列任意一个条件:
- 类型集合中只包含一种类型
- 类型集合中所有类型的底层数据类型均完全相同
在这个例子中,S 使用的结构化约束中,所有满足约束的类型的底层数据类型均为[]E,所以是一个合法的结构化约束。
当存在无法通过函数参数类型推导确定具体类型的类型参数,且类型参数列表中包含结构化约束时,编译器会尝试进行约束类型推导。
推导算法与示例

简单的例子
结合我们刚才的例子“DoubleSlice”函数,讲一下约束类型推导的具体过程:
type MySlice []int
ans := DoubleSlice(MySlice{1, 2, 3})- 1.
- 2.
- 3.
在这个调用中,首先执行的是普通的函数参数类型推导,这一步会得到一个这样的推导结果:
S => MySlice- 1.
此时编译器发现,还有一个类型参数 E 没有被推导,且当前存在一个使用结构化约束的类型参数 S,此时开始约束类型推导。
首先需要寻找已经完成类型推导的类型参数,在这个例子里是 S,它的类型已经被推导出是 MySlice。
然后会将 S 的实际类型“MySlice”,与 S 的结构化约束“~[]E”进行类型统一化,由于 MySlice 的底层类型是[]int,所以结构化匹配之后,得到了这样的匹配结果:
E => int- 1.
此时所有的类型参数都已经被推断,且符合各自的约束,类型推导结束。
一个更复杂的例子
假设有这样一个函数:
func SomeComplicatedMethod[S ~[]M, M ~map[K]V, K comparable, V any](s S) {
// comparable 是一个内置的约束,表示所有可以使用 == != 运算符的类型
}- 1.
- 2.
- 3.
然后我们这样去调用它:
SomeComplicatedMethod([]map[string]int{})- 1.
编译时产生的类型推导过程如下,首先是函数参数类型推导的结果:
S => []map[string]int- 1.
然后对 S 使用约束类型推导,对比 []map[string]int 和 ~[]M,得到:
M => map[string]int- 1.
再继续对 M 使用约束类型推导,对比 map[string]int 和 ~map[K]V,得到:
K => string
V => int- 1.
- 2.
至此类型推导成功完成。
使用约束类型推导保存类型信息
约束类型推导的另一个作用就是,它能够保存调用者的原始参数的类型信息。
还是以这一节的“DoubleSlice”函数做例子,假设我们现在实现一个更加“简单”的版本:
func DoubleSliceSimple[E constraints.Integer](slice []E) []E {
ret := make([]E, 0, len(slice))
for _, item := range slice {
ret = append(ret, item + item)
}
return ret
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
这个版本只有一个类型参数 E。此时我们按照之前的方式去调用它:
type MySlice []int
ans := DoubleSliceSimple(MySlice{1, 2, 3}) // ans 的类型是 []int !!!- 1.
- 2.
- 3.
此时的类型推导仅仅是最基础的函数参数类型推导,编译器会对 MySlice 和[]E 直接做结构化比较,得出 E 的实际类型是 int 的结论。
此时 DoubleSliceSimple 这个函数返回的类型是[]E,也就是[]int,而不是调用者传入的 MySlice。而之前的 DoubleSlice 函数,通过定义了一个使用结构化约束的类型参数 S,并且直接用 S 去匹配入参的类型,且返回值类型也是 S,就可以保留调用者的原始参数类型。
泛型的使用局限
目前 Golang 泛型依然还有不少的局限,几个主要的局限点包括:
- 成员函数无法使用泛型
- 不能使用没在约束定义中指定的方法,即使类型集合里所有的类型都实现了该方法
- 不能使用成员变量,即使类型集合里所有的类型都拥有该成员
下面分别举例:
成员函数无法使用泛型
type MyStruct[T any] struct {
// ...
}
func (s *MyStruct[T]) Method[T2 any](param T2) { // 错误:成员函数无法使用泛型
// ...
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
在这个例子中,MyStruct[T]的成员函数 Method 定义了一个只属于自己的函数参数 T2,然而这样的操作目前是不被编译器支持的(今后也很可能不会支持)。
无法使用约束定义之外的方法
type MyType1 struct {
// ...
}
func (t MyType1) Method() {}
type MyType2 struct {
// ...
}
func (t MyType2) Method() {}
type MyConstraint interface {
MyType1 | MyType2
}
func MyFunc[T MyConstraint](t T) {
t.Method() // 错误:MyConstraint 不包含 .Method() 方法
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
这个例子中,MyConstraint 集合中的两个成员 MyType1 和 MyType2 尽管都实现了.Method()函数,但是也无法直接在泛型函数中调用。
如果需要调用,则应该将 MyConstraint 改写为如下形式:
type MyConstraint interface {
MyType1 | MyType2
Method()
}- 1.
- 2.
- 3.
- 4.
无法使用成员变量
type MyType1 struct {
Name string
}
type MyType2 struct {
Name string
}
type MyConstraint interface {
MyType1 | MyType2
}
func MyFunc[T MyConstraint](t T) {
fmt.Println(t.Name) // 错误:MyConstraint 不包含 .Name 成员
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
在这个例子当中,虽然 MyType1 和 MyType2 都包含了一个 Name 成员,且类型都是 string,也依然无法以任何方式在泛型函数当中直接使用。
因为类型约束本身是一个 interface,而 interface 的定义中只能包含类型集合,以及成员函数列表。
总结
Golang 1.18 带来了上述三个非常重要的新特性,其中:
- 工作区模式可以让本地开发的工作流更加顺畅。
- 模糊测试可以发现一些边边角角的情况,提升代码的鲁棒性。
- 泛型可以让一些公共库的代码更加优雅,避免像以前一样,为了“通用性”不得不采用反射的方式,不仅写起来难写,读起来难受,还增加了运行期的开销,因为反射是运行时的动态信息,而泛型是编译期的静态信息。
本文也是简单讲了这几方面的内容,希望能让大家对 Golang 中的这些新玩意儿有一个基本的了解。
参考文献
- https://go.dev/blog/go1.18
- https://go.dev/blog/intro-generics
- https://go.googlesource.com/proposal/+/refs/heads/master/design/43651-type-parameters.md
- https://go.dev/blog/get-familiar-with-workspaces
- https://go.dev/doc/tutorial/fuzz
- https://tonybai.com/2021/12/01/first-class-fuzzing-in-go-1-18/