自注意力机制属于注意力机制之一。与传统的注意力机制作用相同,自注意力机制可以更多地关注到输入中的关键信息。self-attention可以看成是multi-head attention的输入数据相同时的一种特殊情况。所以理解self attention的本质实际上是了解multi-head attention结构。
一:基本原理
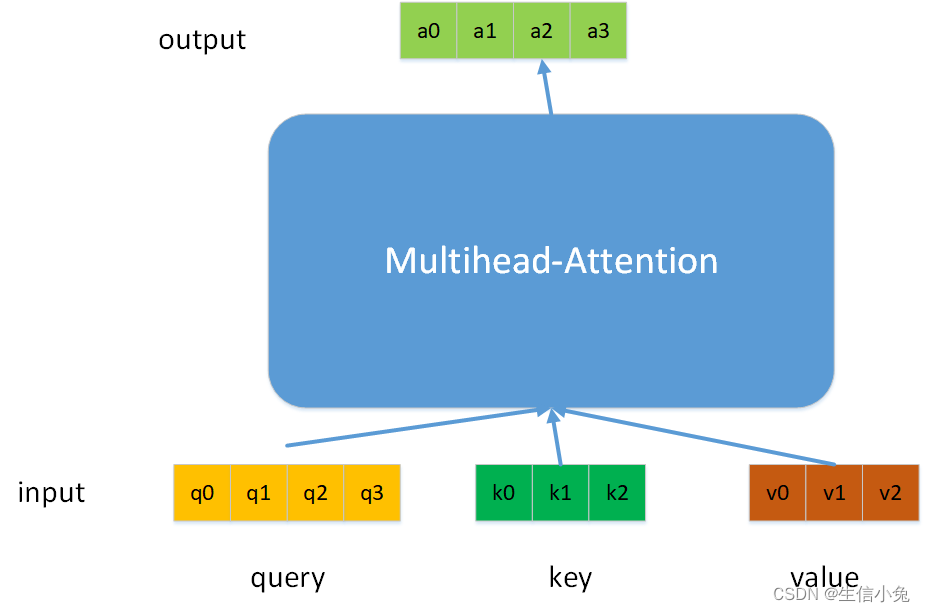
对于一个multi-head attention,它可以接受三个序列query、key、value,其中key与value两个序列长度一定相同,query序列长度可以与key、value长度不同。multi-head attention的输出序列长度与输入的query序列长度一致。兔兔这里记query的长度为Lq,key与value的长度记为Lk。
其次,对于输入序列query、key、value,它们特征长度(每个元素维度dim)是可以不同的,记这三个序列的dim分别为Dq、Dk、Dv。在这些序列输入multi-head attention后,内部的序列的dim是可以与Dq、Dk与Dv不同的,我们称之为嵌入(embedding)维度,记为De,输出的序列dim也是De。
multi-head attention是由一个或多个平行的单元结构组合而成,我们称每个这样的单元结构为一个head(one head,实际上也可以称为一个layer),为了方便,兔兔暂且命名这个单元结构为one-head attention,广义上head数为1 时也是multi-head attention。one-head attention结构是scaled dot-product attention与三个权值矩阵(或三个平行的全连接层)的组合,结构如下图所示
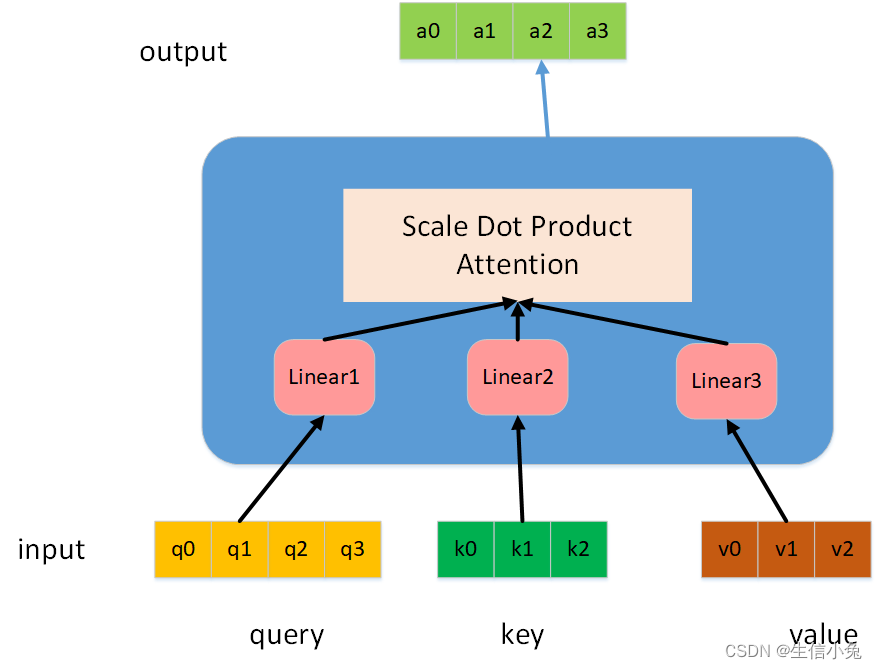
二:Scale Dot-Product Attention具体结构
对于上图,我们把每个输入序列q,k,v看成形状是(Lq,Dq),(Lk,Dk),(Lk,Dv)的矩阵,即每个元素向量按行拼接得到的矩阵。Linear层的参数分别为(Dq,De),(Dk,De),(Dv,De),则通过全连接层,输出矩阵形状为(Lq,De),(Lk,De),(Lv,De),我们令通过全连接层得到的矩阵为Q、K、V。
Linear层的本质是权值矩阵W与输入矩阵相乘(有时也可以加上偏置bias),在one-head attention中,我们令与Q、K、V相乘的权值矩阵分别为,它们的形状为(Dq,De),(Dk,De),(Dv,De)。bias的使用与否对后面的结构并无影响,在一些深度学习框架中默认加bias,但是《Attention Is All You Need》原文公式中并未体现bias,只有W,所以兔兔在后面讲解部分,不考虑bias。
在输入数据通过Linear操作得到Q、K、V矩阵后,我们才真正来到Scale dot-product attention部分。
Scale dot-product attention可以由一个简洁的公式来表示,其中dk即为我们前面的Dk:
这个公式得到的输出即为onehead-attention的输出,它是一个形状为(Lq,De)的矩阵,表示长度为Lq,维度为De的输出序列。公式中:
有一个名字:attention weights,形状为(Lq,Lk),它可以大概理解为q序列与k序列各个对应元素之间相关性,类似于你在网页上输入关键词query,网页中之前存在的索引key,根据query与key的相关与否来决定选哪些索引key,并根据key来推荐相应的value。
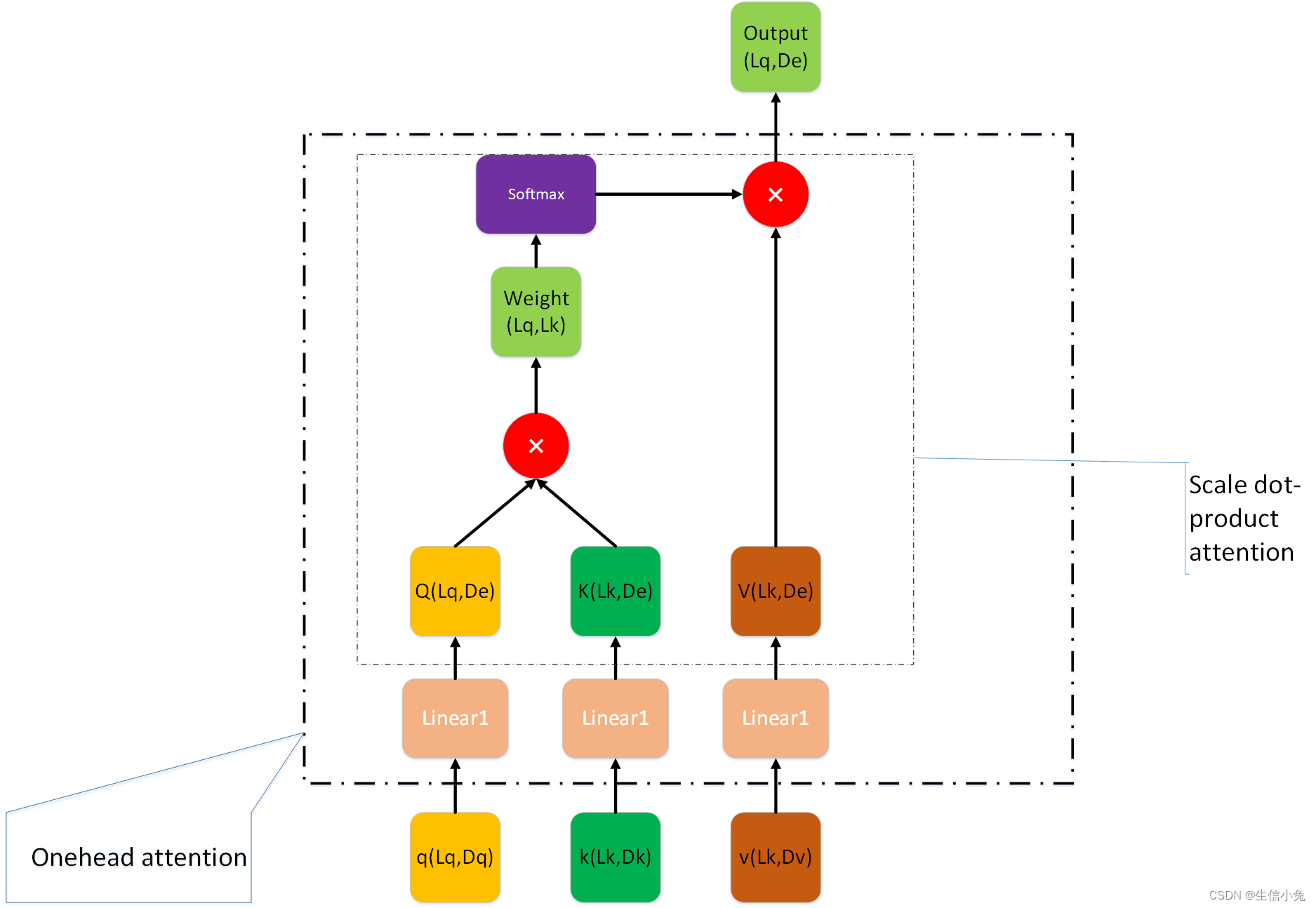
讲到这里,实际上已经介绍完multihead-attention的单元结构了。但是这个过程还可以更加深入地理解,下图是Lq与Lk相同时Scale dot-product attention的详细结构(一般Lq和Lk相等很可能Q,K,v来自同一序列,此时即为self attention,兔兔后面会讲到)。
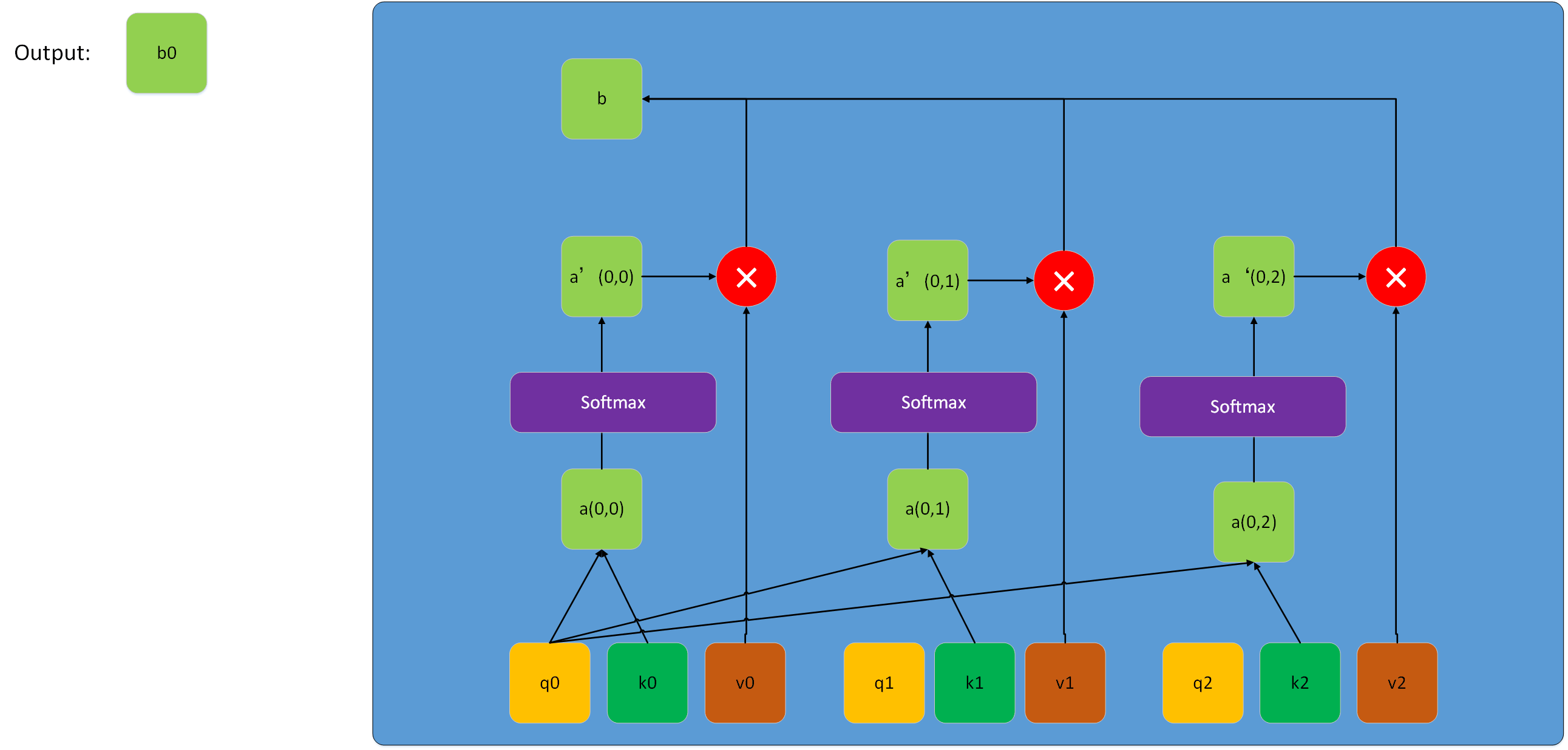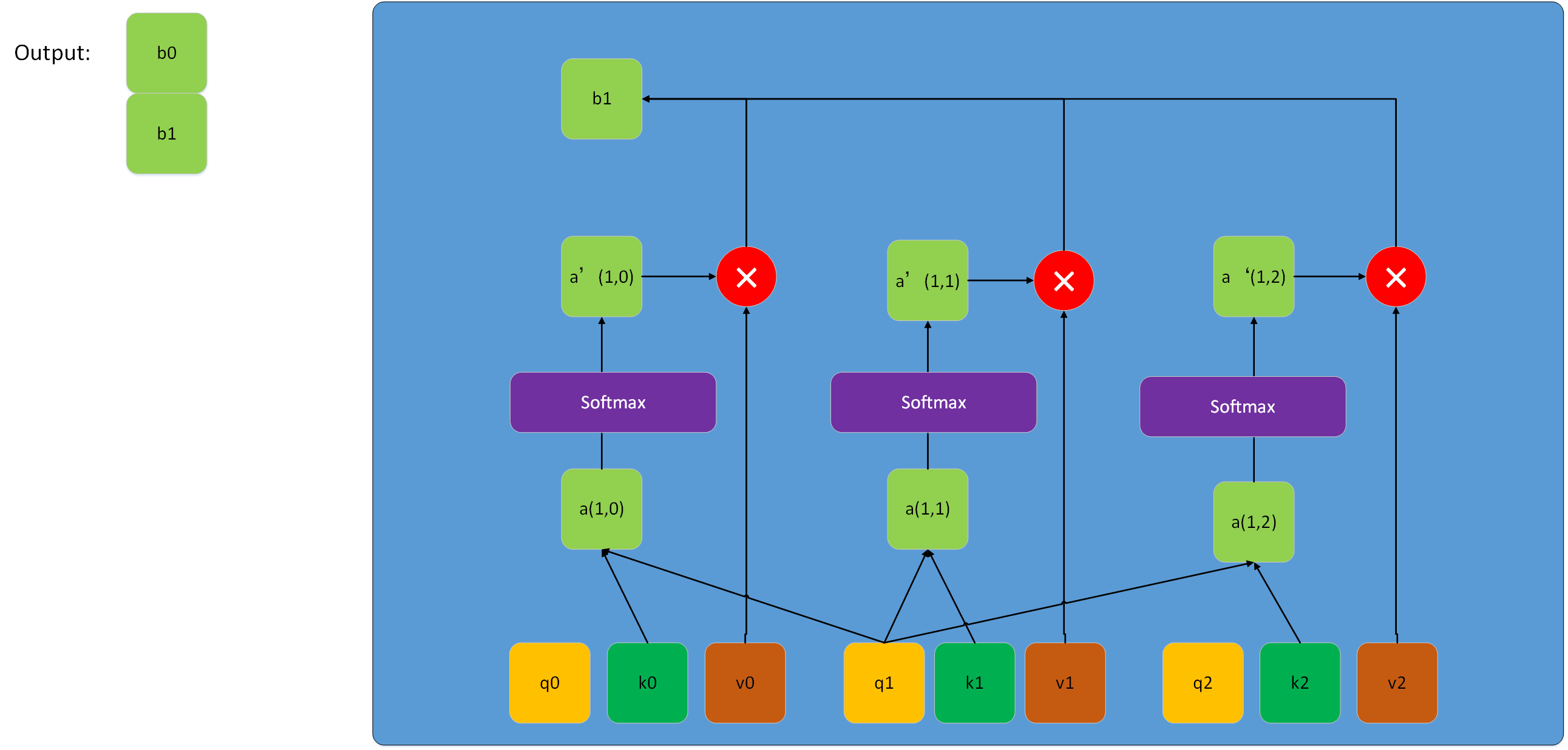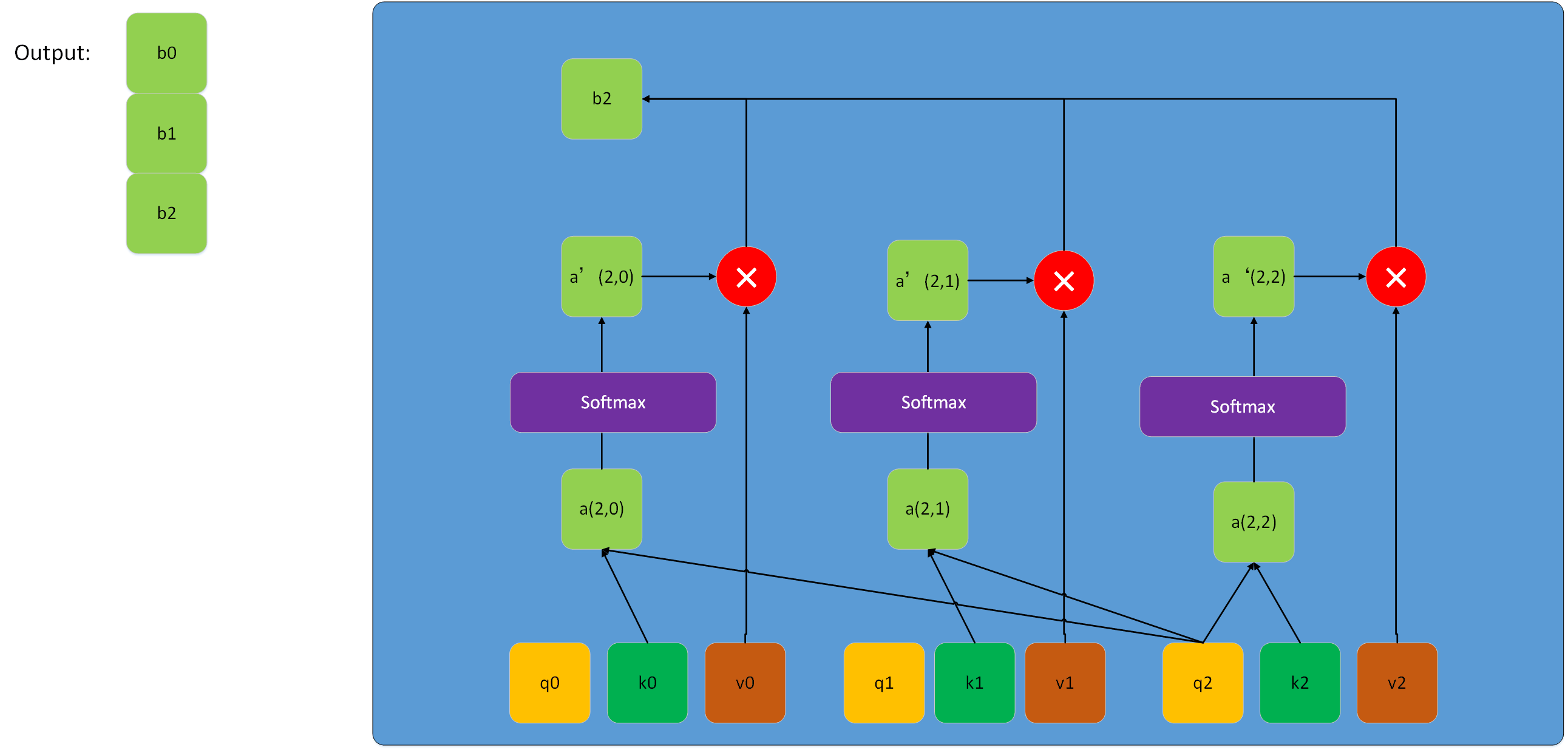
上图展示的是一个接收Q,K,V形状都是(3,De)的一个scale dot-product attention结构,我们把Q、K、V都拆解成长度为3,维度为De的序列。每次q与各个k计算内积得到一个数a,这些数通过softmax得到新的数a'(这里softmax是整体)。得到的a'与各自的v向量相乘得到新的向量,最终这些新的向量相加得到一个长度为De的向量,之后依次计算得到向量b1、b2,把这些向量b拼成矩阵即为最终的输出。对于这个过程,如果把序列q、k、v用前面的矩阵Q、K、V整体表示,实际上就是前面兔兔给出的那个公式,只不过该该公式以矩阵的形式并行运算,使整个计算过程简洁并且速度更快。
当然,Lq在很多情况不一定等于Lk,此时若再用上图表示该过程会很乱。所以兔兔用下图来表示scale dot-product attention过程。
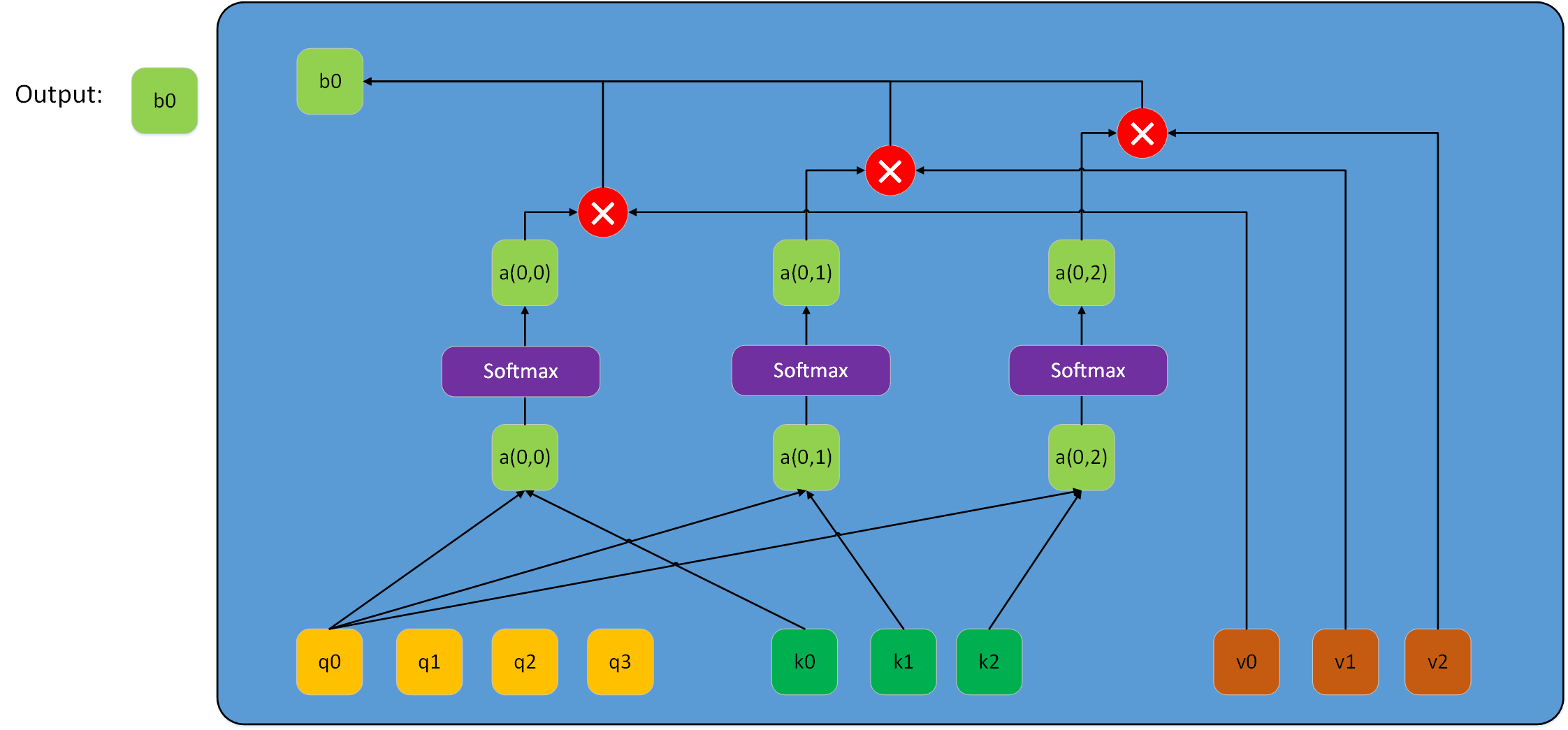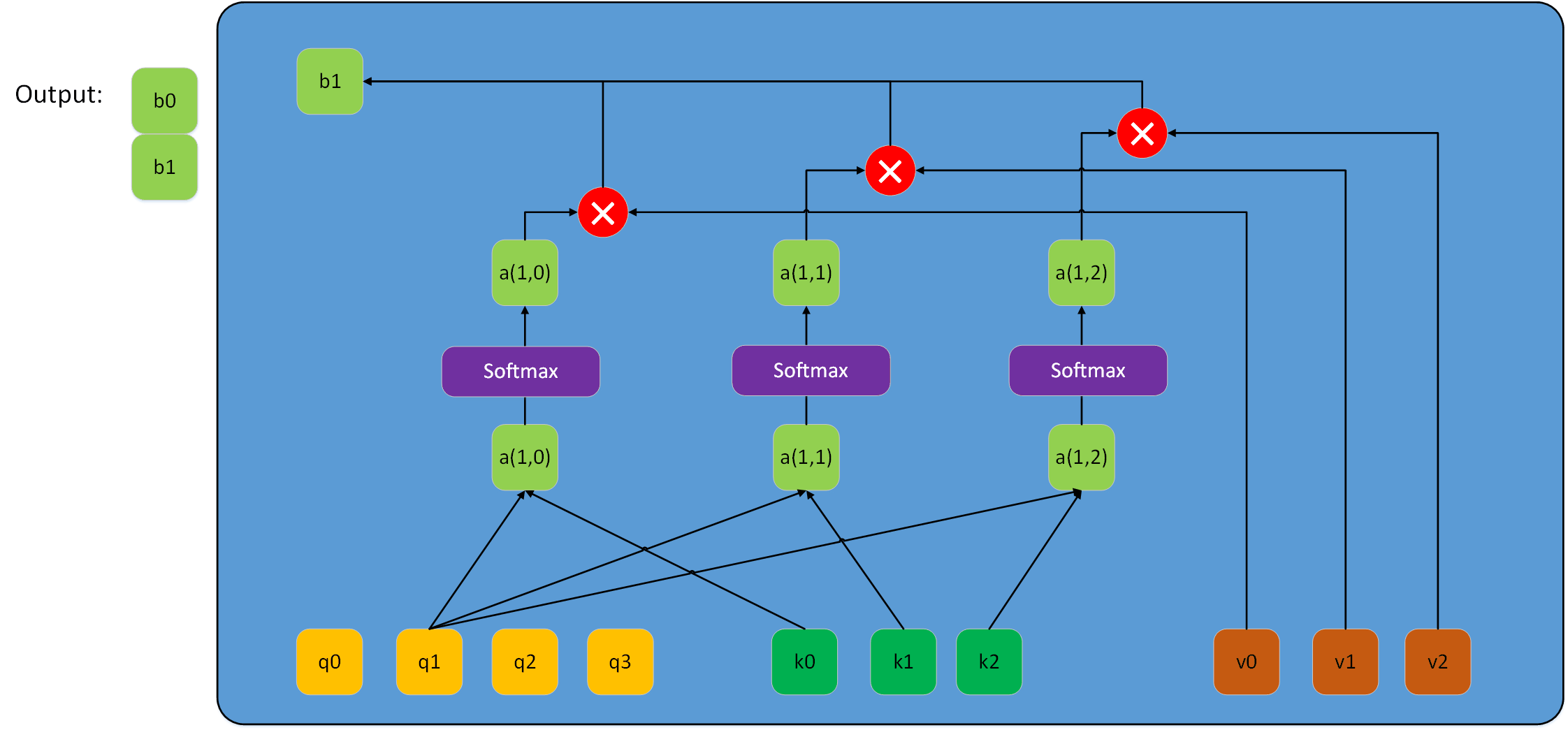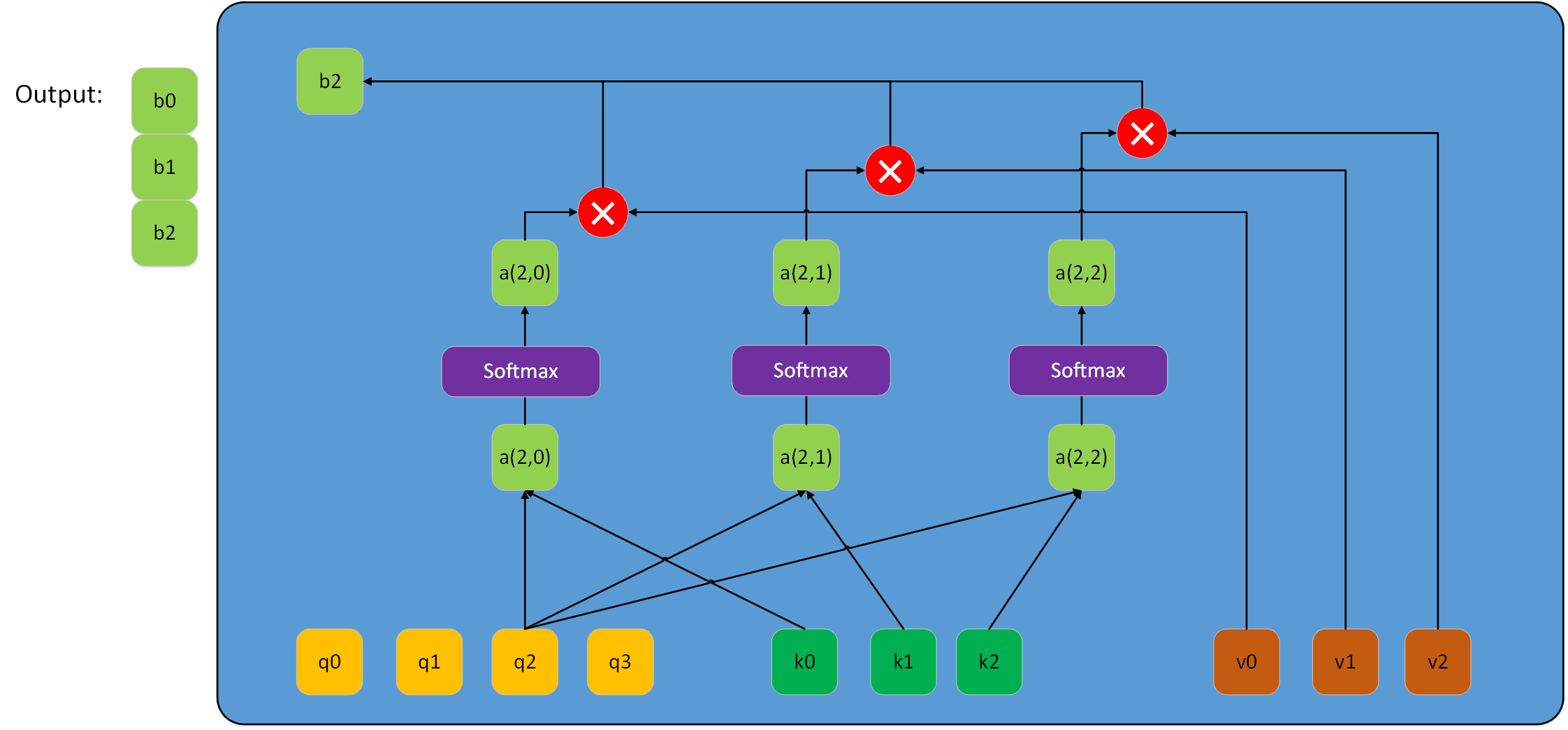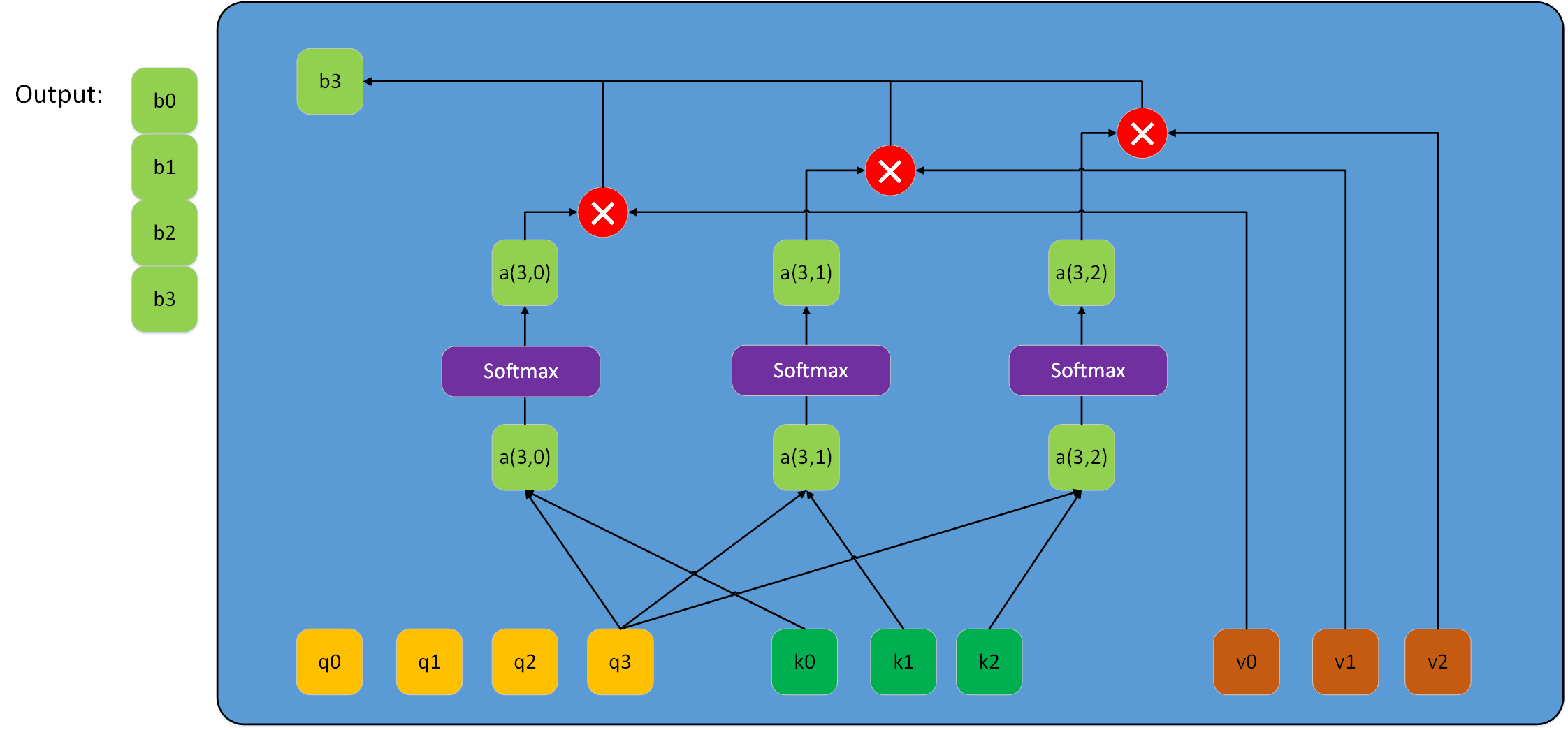
三:Scale Dot-Product Attention中的掩码mask问题
mask在scale dot-product attention中是可有可无的,在有些情况下使用mask效果会更好,有时则不需要mask。mask作用于scale dot-product attention中的attention weight。前面讲到atttention weights形状是(Lq,Lk),而使用mask时一般是self-attention的情况,此时Lq=Lk,attention weights 为方阵。mask的目的是使方阵上三角为负无穷(或是一个很小的负数),只保留下三角,这样通过softmax后矩阵上三角趋近于0。这样处理的目的是考虑到实际应用中的情况,例如翻译任务中,我们希望在读取句子序列时每次只利用前面读过的词,与后面还没有读到的词句无关。
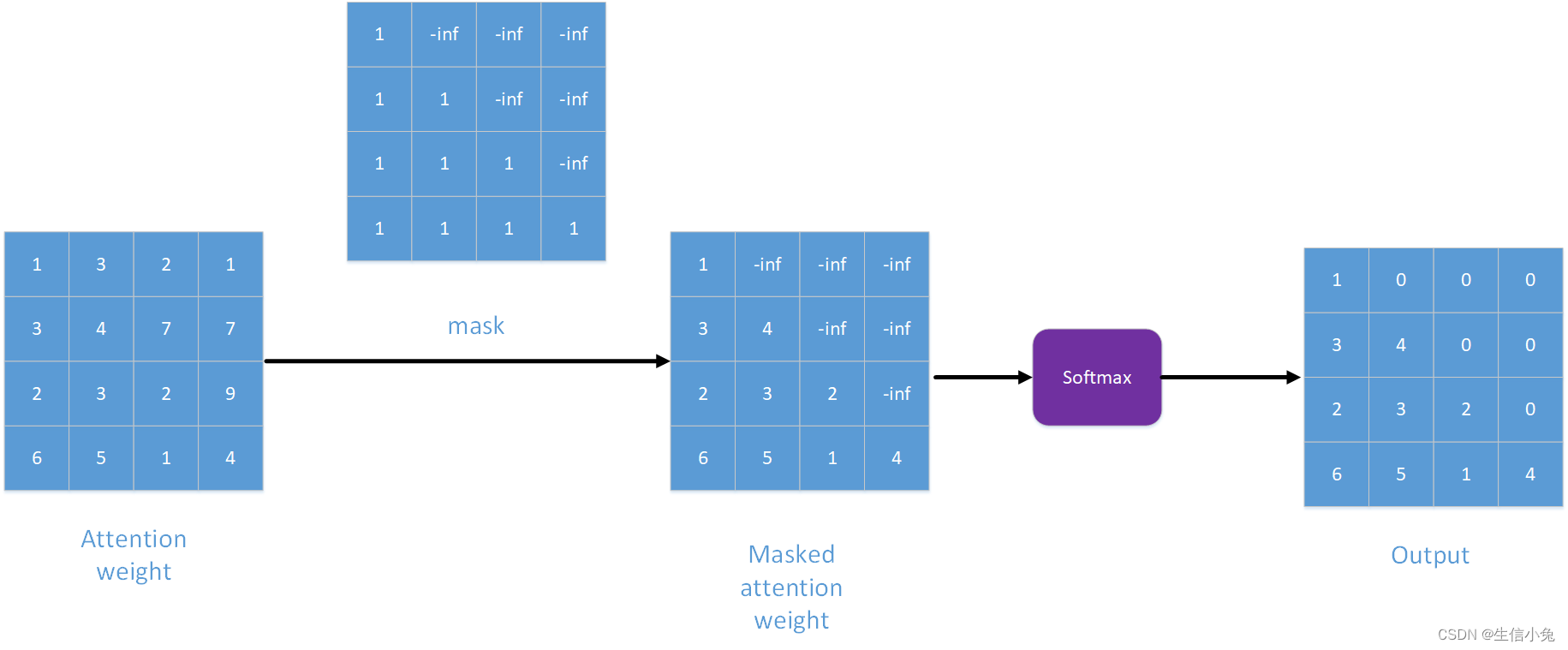
实际上,mask的种类可以不止是掩去上三角,根据实际情况也可以使矩阵右侧某些列或任意某些位置为-inf,来掩掉这些位置的信息。
对于multi-head attention,如果使用mask,则每个head一般都使用相同的mask,此时该模型也称为masked multihead-attention
- import numpy as np
- import torch
-
- weight=torch.randint(0,5,size=(5,5))
- mask=torch.tensor(np.array([[False,True,True,True,True],
- [False,False,True,True,True],
- [False,False,False,True,True],
- [False,False,False,False,True],
- [False,False,False,False,False]]))
- masked_weight=weight.masked_fill(mask,-1000)
- out=nn.Sigmoid()(masked_weight)
- print(masked_weight)
- print(out)
- '''-------------------------------'''
- >>>tensor([[ 0, -1000, -1000, -1000, -1000],
- [ 3, 4, -1000, -1000, -1000],
- [ 3, 2, 0, -1000, -1000],
- [ 4, 3, 1, 2, -1000],
- [ 2, 3, 0, 2, 3]])
- >>>tensor([[0.5000, 0.0000, 0.0000, 0.0000, 0.0000],
- [0.9526, 0.9820, 0.0000, 0.0000, 0.0000],
- [0.9526, 0.8808, 0.5000, 0.0000, 0.0000],
- [0.9820, 0.9526, 0.7311, 0.8808, 0.0000],
- [0.8808, 0.9526, 0.5000, 0.8808, 0.9526]])

四:Multi-Head Attention结构
multi-head attention由多个one-head attention组成。我们记一个multi-head attention有n个head,第i个head的权值分别为,则:
这个过程为:输入q,k,v矩阵分别输入各one-head attention,各个head输出矩阵按特征(dim)维度拼接得到新的矩阵,再与矩阵相乘即得到输出(实际上也可以是一个全连接层Linear),并且输出形状仍是(Lq,De)。
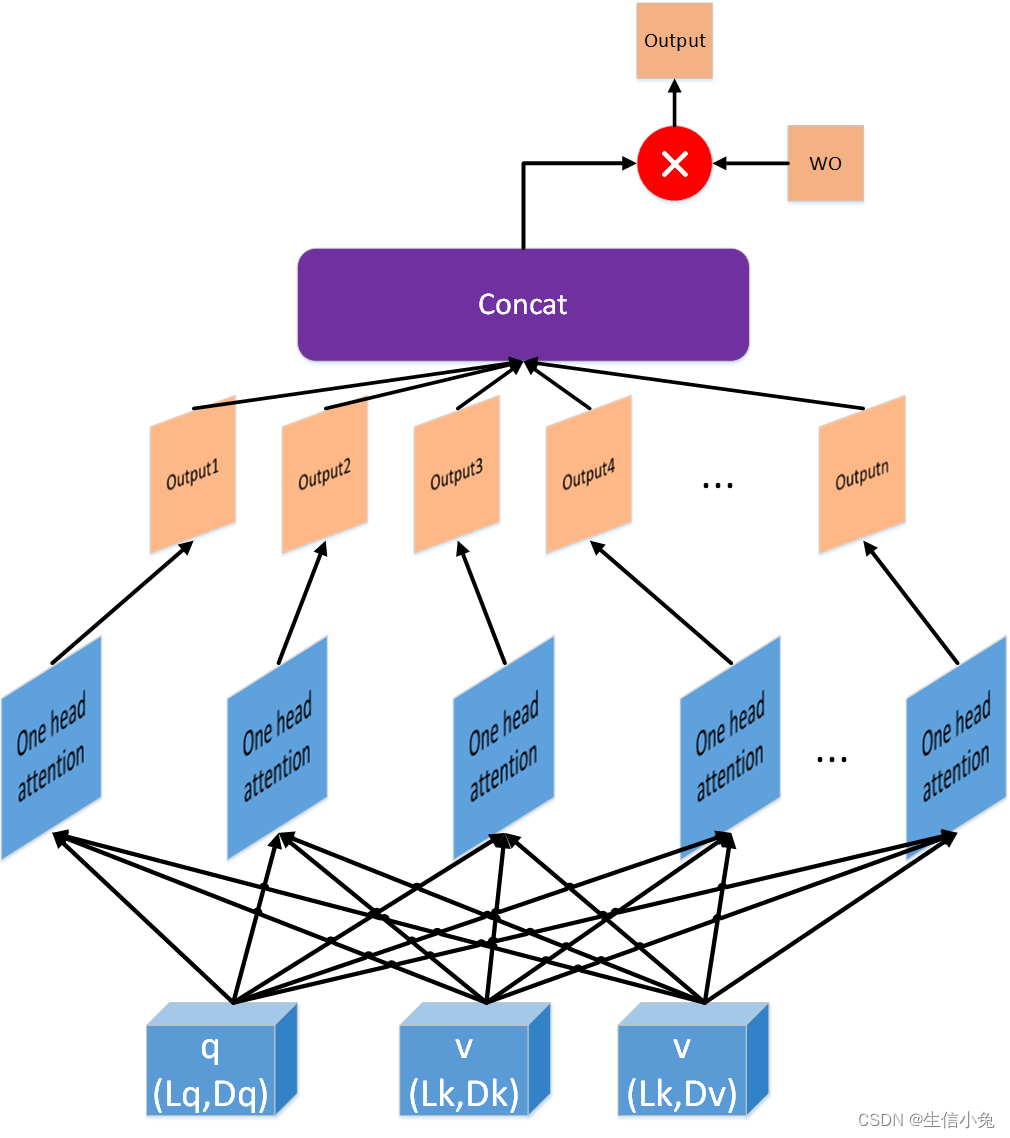
关于其中的参数W,实际上可能会有两种情况,
(1)的形状为:(Lq,De),(Lk,De),(Lk,De),则每个head形状为(Lq,De),拼接后得到的矩阵形状(Lq,n×De),
形状为:(n×De,De)。
(2)的形状为:(Lq,De/n),(Lk,De/n),(Lk,De/n)(此时要保证嵌入维度De能整除head数n),则每个head的形状为(Lq,De/n),拼接后得到的矩阵形状(Lq,De),
形状为:(De,De)。
虽然这两种方式内部参数不同,但输入与输出数据形状不变。Pytorch中的MuitiheadAttention使用的是方法(2)。
四:对self-attention的理解
self-attention是multi-head attention三个输入序列都来源于同一序列的情况。设输入序列为input,此时输入的q,k,v三个序列全是input,所以此时Lq=Lk,Dq=Dk=Dv。由于所有输入都是同一个序列,所以也很好理解为什么叫做自注意力。
五:query、key、value的理解与来源
query、key、value分别为查询、键、值。它们可以由同一个序列得到,也可以是具有实际意义的不同序列。从检索的角度来看,query是需要检索的内容,key是索引,value为待检索的值,attention的过程是计算query与key的相关性,获得attention map,在利用 attention map获取value中的特征值。在self-attention中,query,key,value为同一序列,一般情况下,query为一个序列,key与value为同一序列,更一般情况,query,key,value为三个不同的序列。
六:应用实例
1.使用Pytorch构建multi-head attention
- class attention(nn.Module):
- def __init__(self,embed_dim,num_heads):
- '''
- :param embed_dim: 嵌入特征个数
- :param num_heads: scale dot-product attention层数
- '''
- super(attention, self).__init__()
- self.embed_dim=embed_dim
- self.num_heads=num_heads
- self.w_q=[nn.Linear(embed_dim,embed_dim) for i in range(num_heads)]
- self.w_k=[nn.Linear(embed_dim,embed_dim) for i in range(num_heads)]
- self.w_v=[nn.Linear(embed_dim,embed_dim) for i in range(num_heads)]
- self.w_o=nn.Linear(embed_dim*num_heads,embed_dim)
- self.softmax=nn.Softmax()
- def single_head(self,q,k,v,head_idx):
- '''scale dot-scale attention '''
- q=self.w_q[head_idx](q)
- k=self.w_k[head_idx](k)
- v=self.w_v[head_idx](v)
- out=torch.matmul(torch.matmul(q,k.permute(0,2,1)),v)/self.embed_dim
- return out
- def forward(self,q,k,v):
- output=[]
- for i in range(self.num_heads):
- out=self.single_head(q,k,v,i)
- output.append(out)
- output=torch.cat(output,dim=2)
- output=self.w_o(output)
- print(output.shape)
- return output
-
- if __name__=='__main__':
- x=torch.randn(size=(3,2,8),dtype=torch.float32)
- q,k,v=x,x,x
- att=attention(embed_dim=8,num_heads=4)
- output,attention_weight=att(q,k,v)
2.使用Pytoch中nn.MultiheadAttention方法
在Pytorch中,MultiheadAttention方法中必需参数有2个:
embed_dim:嵌入维度,即De。
num_heads:head数
虽然前面讲到Dq、Dk、Dv、De是可以不等的,但是pytorch中输入的Dq要等于De,并且默认Dv、De也等于De,如果k,v的特征dim不等于De,需要修改kdim,vdim参数。对于接收的数据,pytorch默认形式是(seq,batch,feature),即第一个维度是序列长度,第二个是batch size,第三个是特征dim。如果我们习惯于(batch,seq,feature)形式,可以修改参数batch_first=True。
- import torch
- from torch import nn
- q=torch.randint(0,10,size=(10,9,8),dtype=torch.float32) #batch_size,seq_length,dim
- k=torch.randint(0,10,size=(10,7,4),dtype=torch.float32)
- v=torch.randint(0,10,size=(10,7,3),dtype=torch.float32)
- attention=nn.MultiheadAttention(embed_dim=8,num_heads=4,kdim=4,vdim=3,batch_first=True)
- attn_output, attn_output_weights=attention(q,k,v)
- print(attn_output.shape)
- print(attn_output_weights.shape)
当然,除了这些参数,pytorch的MultiheadAttention中还有更多的参数,例如各种bias,表示是否加入偏置。
七:总结
自注意力机是multi-head attention模型在所有输入都是同一序列一种情况。multi-head attention结构上是一个或多个one head attention 平行组合。每个one head attention由scale dot-product attention与三个相应的权值矩阵组成。multi-head attention作为神经网络的单元层种类之一,在许多神经网络模型中具有重要应用,并且它也是当今十分火热的transformer模型的核心结构之一,掌握好这部分内容对transformer的理解具有重要意义。