如果让我们自己去做搜索的话,我们能够想到的是文章和搜索词的相关性,以此来判断这个文章是否是我们想要的,最开始的搜索有的是这样做的,还有的是按照网站的种类做个大的索引表,但是可以索引的关键字有限。
互联网上的网页估计有千百亿规模了(猜测),那么显然不是所有包含搜索关键字的网页都同等重要。有的在标题中包含关键字,有的在文档中包含关键字;有的是权威机构网站,有的是个人博客,显然在给用户返回网页的时候,比较重要的网页的应该排在前面,不重要的网页信息排在后面。那又来一个问题,如何确定一个网页的重要性那。
网页是通过链接来组织的,那么我们可以把整个互联网看成一张大的图,每个节点为一个个网页,网页之间的链接看成边。网页是否重要,要看是否有多个网页链接到它。被越多网页链接的网页越重要,当然链接这个网页的多个链接的重要性又是不相同的。
假设我们搜索得到很多网页,其中一个网页Y的排名应该来自所有指向这个网页X1,X2,X3的权重之和:
Y网页的权重 = X1+X2+X3...+Xn
而X1,X2,...Xn的权重分别是多少,如何度量,这又需要通过链接到它的网页的权重来计算,这样循环往复,就无解了。据说是Google的布林破解了这个怪圈,就是开始的时候给每个网页设置相同的初始值,那么经过多轮计算后,这个算法可以保证网页排名多次之后回收敛到排名的真实值。
我理解下,大概是这样子的:
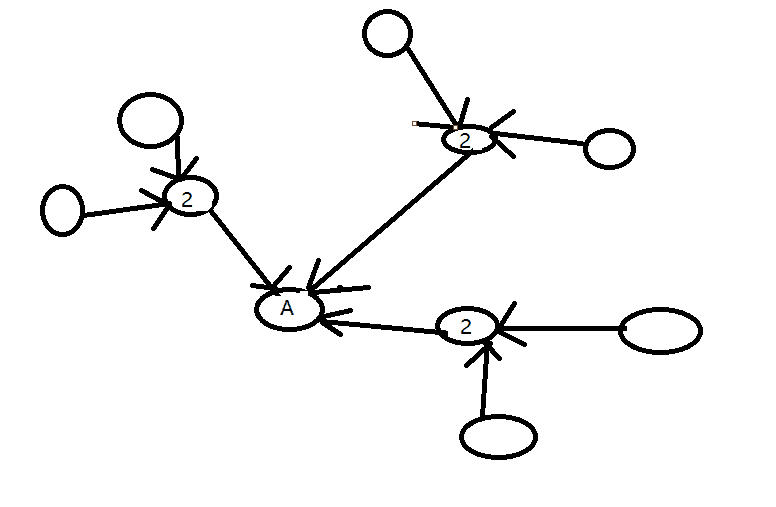
第一轮的时候,我们假设所有网页的权重都是1,那么A这个网页的权重为1+1+1为3, 第二轮计算的时候,与A相连的网页权重变成了2,那么最终A这个网页的权重就变成了2+2+2=6,这样多次计算后,被更多权重高的网页链接的网页,排名靠前,其他的靠后。
这整个过程有点类似于民主选举,选举过程中每个人的票的权重又是不一样的,这和现实也很类似。 那么PageRank算法除了计算网页排名还有什么用那,数据实战45讲里面,有个例子比较有意思,计算泄露出来希拉里邮件列表中的人物影响力的情况,通过python的networkx库可以方便地计算PageRank的值。
下面的网络图的:

简单的计算PageRank的代码:
import networkx as nx
# 创建有向图
G = nx.DiGraph()
# 有向图之间边的关系
edges = [("B1", "B"), ("B2", "B"), ("C1", "C"), ("C2", "C"), ("D1", "D"), ("D2", "D"), ("D", "A"), ("C", "A"), ("B", "A")]
for edge in edges:
G.add_edge(edge[0], edge[1])
pagerank_list = nx.pagerank(G, alpha=1)
print("pagerank值是:", pagerank_list)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
结果:

整个数据集合分为三个文件:Aliases.csv,Emails.csv和Persons.csv,其中Emails文件为邮件内容,包括重要的发送者和接收者信息。 Persons文件统计邮件中所有人的姓名和对应ID。 下面代码是数据实战中的代码直接拿过来了,其实过程也是比较简单,只是这个思路比较重要。
# -*- coding: utf-8 -*-
# 用 PageRank 挖掘希拉里邮件中的重要任务关系
import pandas as pd
import networkx as nx
import numpy as np
from collections import defaultdict
import matplotlib.pyplot as plt
# 数据加载
emails = pd.read_csv("./input/Emails.csv")
# 读取别名文件
file = pd.read_csv("./input/Aliases.csv")
aliases = {}
for index, row in file.iterrows():
aliases[row['Alias']] = row['PersonId']
# 读取人名文件
file = pd.read_csv("./input/Persons.csv")
persons = {}
for index, row in file.iterrows():
persons[row['Id']] = row['Name']
# 针对别名进行转换
def unify_name(name):
# 姓名统一小写
name = str(name).lower()
# 去掉, 和 @后面的内容
name = name.replace(",","").split("@")[0]
# 别名转换
if name in aliases.keys():
return persons[aliases[name]]
return name
# 画网络图
def show_graph(graph, layout='spring_layout'):
# 使用 Spring Layout 布局,类似中心放射状
if layout == 'circular_layout':
positions=nx.circular_layout(graph)
else:
positions=nx.spring_layout(graph)
# 设置网络图中的节点大小,大小与 pagerank 值相关,因为 pagerank 值很小所以需要 *20000
nodesize = [x['pagerank']*20000 for v,x in graph.nodes(data=True)]
# 设置网络图中的边长度
edgesize = [np.sqrt(e[2]['weight']) for e in graph.edges(data=True)]
# 绘制节点
nx.draw_networkx_nodes(graph, positions, node_size=nodesize, alpha=0.4)
# 绘制边
nx.draw_networkx_edges(graph, positions, edge_size=edgesize, alpha=0.2)
# 绘制节点的 label
nx.draw_networkx_labels(graph, positions, font_size=10)
# 输出希拉里邮件中的所有人物关系图
plt.show()
# 将寄件人和收件人的姓名进行规范化
emails.MetadataFrom = emails.MetadataFrom.apply(unify_name)
emails.MetadataTo = emails.MetadataTo.apply(unify_name)
# 设置遍的权重等于发邮件的次数
edges_weights_temp = defaultdict(list)
for row in zip(emails.MetadataFrom, emails.MetadataTo, emails.RawText):
temp = (row[0], row[1])
if temp not in edges_weights_temp:
edges_weights_temp[temp] = 1
else:
edges_weights_temp[temp] = edges_weights_temp[temp] + 1
# 转化格式 (from, to), weight => from, to, weight
edges_weights = [(key[0], key[1], val) for key, val in edges_weights_temp.items()]
# 创建一个有向图
graph = nx.DiGraph()
# 设置有向图中的路径及权重 (from, to, weight)
graph.add_weighted_edges_from(edges_weights)
# 计算每个节点(人)的 PR 值,并作为节点的 pagerank 属性
pagerank = nx.pagerank(graph)
# 将 pagerank 数值作为节点的属性
nx.set_node_attributes(graph, name = 'pagerank', values=pagerank)
# 画网络图
show_graph(graph)
# 将完整的图谱进行精简
# 设置 PR 值的阈值,筛选大于阈值的重要核心节点
pagerank_threshold = 0.005
# 复制一份计算好的网络图
small_graph = graph.copy()
# 剪掉 PR 值小于 pagerank_threshold 的节点
for n, p_rank in graph.nodes(data=True):
if p_rank['pagerank'] < pagerank_threshold:
small_graph.remove_node(n)
# 画网络图,采用circular_layout布局让筛选出来的点组成一个圆
show_graph(small_graph, 'circular_layout')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.