使用但不常见的方法
filter、map、skip等方法想必大家都十分熟悉 无需赘述。这里仅介绍工程中使用较少但同样实用的方法。
▐ reduce
reduce有3个参数:初始值、累加器、组合器。下面通过几个case为大家逐一讲解。由于比较绕,下面贴上ide执行结果
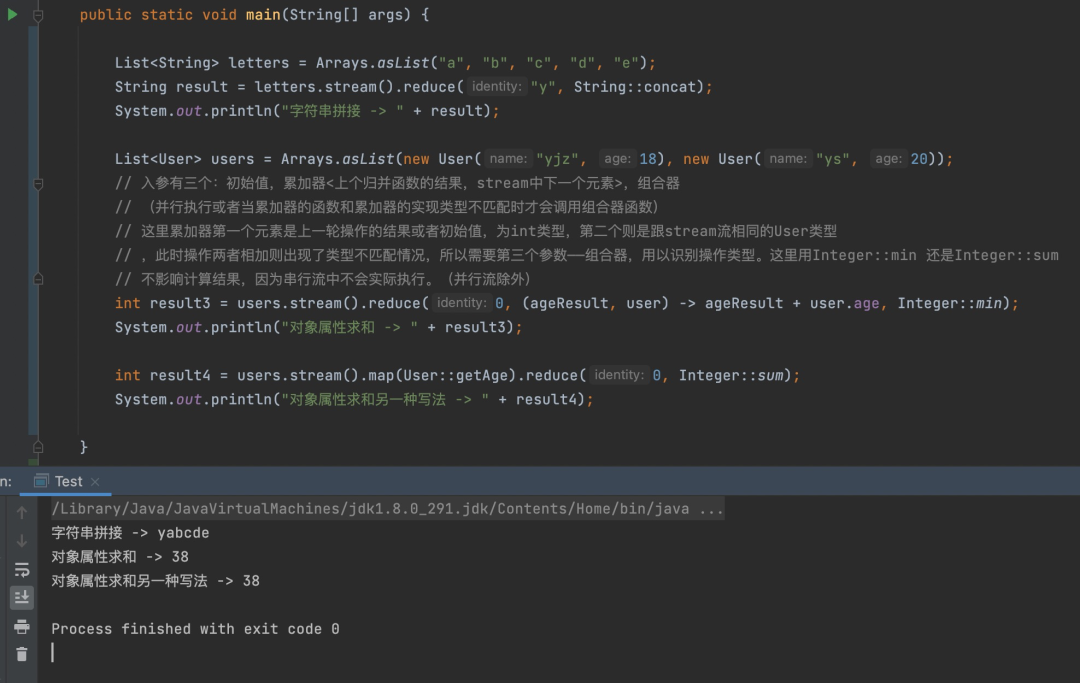
当顺序读流或者累加器的参数和它的实现的类型匹配时,我们不需要使用组合器。通常只有在处理对象属性时则需要组合器来帮助编译器推断入参类型。实际在串行流中组合器并不会实际执行,只需要出入参类型满足编译器推断要求即可。可以看到上方result3的计算,末尾组合器适用max还是min 结果是一样的。
▐ allMatch/anyMatch/noneMatch
判断集合中是否 全部都匹配/存在任意匹配/不存在匹配 某一规则。
比如下面一段代码,判断集合中的对象是否全部合法。语义十分简单。下面对比stream写法和常规写法。两种写法的运行结果是一样的。
@Data
@AllArgsConstructor
public static class Calendar {
private LocalDate date;
private boolean today;
private boolean signed;
}
//日历初始化
LocalDate now = new LocalDate();
List<Calendar> calendars = Arrays.asList(
new Calendar(new LocalDate(1661174238000L), false, false)
, new Calendar(new LocalDate(1661828371000L), false, false)
, new Calendar(new LocalDate(1661433438000L), false, false)
, new Calendar(new LocalDate(1661519838000L), false, false)
, new Calendar(new LocalDate(1661779038000L), false, false)
, new Calendar(now, true, true)
);
//判断昨天是否签到过。写法一
boolean yesterdaySigned = calendars.stream()
.anyMatch(
t -> Days.daysBetween(t.getDate(), now).getDays() == 1 && t.isSigned()
);
System.out.println("昨天是否签到过 -> " + yesterdaySigned);
//写法二
boolean yesterdaySigned2 = false;
for (Calendar calendar : calendars) {
if (Days.daysBetween(calendar.getDate(), now).getDays() == 1) {
//找到昨天的日历,并判断是否签到
yesterdaySigned2 = calendar.isSigned();
break;
}
}
System.out.println("昨天是否签到过写法二 -> " + yesterdaySigned2);- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
这里写法一虽然更简练但是存在问题,大家有看出来的吗。这个问题放在“注意事项”中专门讲解。
▐ flatMap
跟map的区别是可以将一个对象转化成多个对象并以流的方式返回,适合用于集合嵌套场景下的扁平化处理。概念较为拗口,以下用ide截图演示。可以看到特定场景下flatmap相对map有先天优势。

注意事项
▐ 书写顺序影响性能
stream实际使用中,filter和map最为常见。这两个操作都是逐个元素执行并逐个向下游操作传递,我们称之为“垂直操作”(补充:sorted是“水平操作”,即会截断后续运算直至自己将流中所有元素操作完成)。其中filter较为特殊,被其拦截后不会继续向下游传递。基于此原理,尽可能将filter前置往往可以大幅提高stream操作性能。如下所示:

一个长度为5的字符集,map-filter-foreach 顺序执行 则会有5次map、5次filter、1次foreach;
filter-map-foreach顺序执行,则会有5次filter、1次map、1次foreach执行。并且很容易推断filter过滤度越高性能差异就会越明显。
原理不少人可能会觉得简单易懂,但遗憾的是在大型项目中往往总能找到有此类性能缺陷的代码,诸如
List<Long> awardId = timeFilterAwardConfigs.stream()
.map(config -> config.getAwardId())
.filter(awardId -> awardId > 0)
.collect(Collectors.toList());- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
但在更复杂的场景下,也并非要求filter无脑提前于其他操作。比如下面这个例子
//假设一份用户集
List<User> userList = Arrays.asList(
new User("张三", 22)
, new User("李四", 21)
, new User("王五", 19)
, new User("赵六", 25)
);
//要输出这份集合中所有用户所就职的公司的年度营业额总和,要求公司所在地都在杭州市余杭区
// 注意用户中可能有无业游民。不考虑就职公司重合或者一人就职多家公司的情况。
//写法一
int allCompanyTurnover1 = userList.stream()
.map(user -> calculateAnnualTurnover(queryUserCompany(user)))
.filter(Objects::nonNull)
.reduce(0, Integer::sum);
//写法二
int allCompanyTurnover2 = userList.stream()
.filter(user -> {
Company company = queryUserCompany(user);
return company != null && !"余杭".equals(company.getLocal());
})
.map(user -> calculateAnnualTurnover(queryUserCompany(user)))
.reduce(0, Integer::sum);- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
写法一显然更符合直觉,写法二虽然filter提前过滤掉了一部分数据,但是queryUserCompany存在重复计算。所以此种情况下就需要综合 filter过滤度和queryUserCompany重复计算的开销进行权衡。如果filter过滤度足够高(比如余杭的公司很少)同时queryUserCompany 资源开销不大,那么写法二更优,反之写法一更优。
▐ 并非适用所有场景
- 性能上
这里就可以说回到刚才讲anyMatch时看到的那段代码
//判断昨天是否签到过。写法一
boolean yesterdaySigned = calendars.stream()
.anyMatch(
t -> Days.daysBetween(t.getDate(), now).getDays() == 1 && t.isSigned()
);
System.out.println("昨天是否签到过 -> " + yesterdaySigned);
//写法二
boolean yesterdaySigned2 = false;
for (Calendar calendar : calendars) {
if (Days.daysBetween(calendar.getDate(), now).getDays() == 1) {
//找到昨天的日历,并判断是否签到
yesterdaySigned2 = calendar.isSigned();
break;
}
}
System.out.println("昨天是否签到过写法二 -> " + yesterdaySigned2);- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
打印观察执行次数如下

显然 anyMatch 会无条件遍历所有元素再返回,而直观的遍历写法往往不会犯这种错误,拿到结果后可以提前break。大家可能会想到先利用filter过滤获获取“昨天”的日历,然后再anymatch
boolean yesterdaySigned = calendars.stream()
.filter(t -> Days.daysBetween(t.getDate(), now).getDays() == 1)
.anyMatch(Calendar::isSigned);- 1.
- 2.
- 3.
- 4.
- 5.
但是很可惜,filter同样会完整遍历整个集合。事实上遍观所有stream方法似乎都没有办法很好的解决这个问题。也欢迎大家一起探讨。
- 可阅读性
摘取了某业务中判断周期内签到次数的方法,采用stream和for循环常规写法
private int getCycleActionCount(Date start, Date end, List<ActionCalendar> calendar) {
int count = 0;
for (ActionCalendar calendarDay : calendar) {
Date date = calendarDay.getDate();
if (date.after(start) && date.before(end) && calendarDay.isComplete()) {
//在周期内任意一天签到,签到次数自增。
count++;
}
}
return count;
}
private int getCycleActionCount2(Date start, Date end, List<ActionCalendar> calendar) {
return Math.toIntExact(
calendar.stream()
.filter(
//统计周期内签到天数
t -> (
t.getDate().after(start) && t.getDate().before(end) && t.isComplete()
)
).count()
);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
这样看两者之间 光从可阅读性上看并没有特别大的区分度。而即使熟练的stream 爱好者,相信写出一段stream代码后也会多看几眼确认性能、缩进是否达到最优。可见在某些场景下无论性能、可读性还是书写便利性都不占优,此时stream似乎就不是最优选择了。
总结
stream在多数场景下都能帮助我们更快的写出优美的代码,但是在更为复杂的场景下则需要对API之间的执行顺序、lambda表达式的使用、甚至此场景是否适用stream写法进行一定的思考,以避免出现性能或可读性的缺陷。
总的来看stream和直观的for遍历是互补而非替代关系,两者搭配,干活不累。
此外stream家族中还有个强大的种子选手“parallelStream”(并行流)没有介绍。他通常用在超大集合的处理中,日常工程中难寻使用场景,同时使用上比上面说到的串行流处理有更多的注意事项。这里暂不展开分享。