简单三步 !用自己的数据集快速训练Yolov5模型
文章目录
- 简单三步 !用自己的数据集快速训练Yolov5模型
- 1 第一步;准备好划分完的数据集
- 2 第二步;写一个数据集的配置文件
- 3 第三步;修改train.py参数
- 4 小知识💡:标签内容解释
- 5 常见问题🌟
- 本人更多YOLOv5实战内容导航🍀🌟🚀
网上关于Yolov5如何标注数据集的文章很多,如果大家嫌麻烦可以看我这篇文章介绍的标注工具,可以直接标注成YOLO格式的
下面直接通过一种简单明了的方式让大家迅速的开始训练自己的数据集;
相信大家在运行Yolov5时coco128数据集已经下载好了,coco128数据集默认的位置就是我们项目代码的同级目录,所以我以这个位置作为参考,通过对比的方式让大家迅速了解读取数据集的原理;
这次我使用的是划分好了的数据集,所以并没有介绍如何去划分数据集,如果大家需要会补上的;
1 第一步;准备好划分完的数据集
将解压好的数据集放到datasets文件夹下,dataset文件夹是我们在运行项目时自动创建的,dataset文件夹里面已经有了coco128数据集,放好之后应该就是下面树形结构的样子
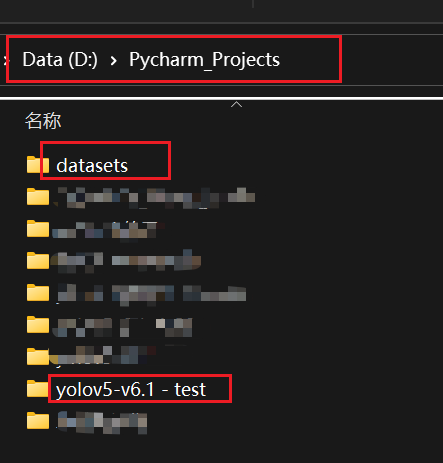
检查数据集是否按照这样的方式去命名,这里注意的是image文件夹下的“train”和“val”要与lables文件夹下的“train”和“val”名字一致
D:\PYCHARM_PROJECTS
├─yolov5-v6.1-test
└─datasets
├─coco128
│ ├─images
│ │ └─train2017>图片.jpg
│ └─labels
│ └─train2017>标签.txt
└─mydata
├─images
│ ├─train>图片.jpg
│ └─val>图片.jpg
└─labels
├─train>标签.txt
└─val>标签.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2 第二步;写一个数据集的配置文件
写一个配置文件放在你项目源代码的data文件夹里

这是我自己写的cars.yaml,书写方式我们可以参照coco128.yaml,然后把我们自己数据集的路径放进来;test集是可选的,写不写都行
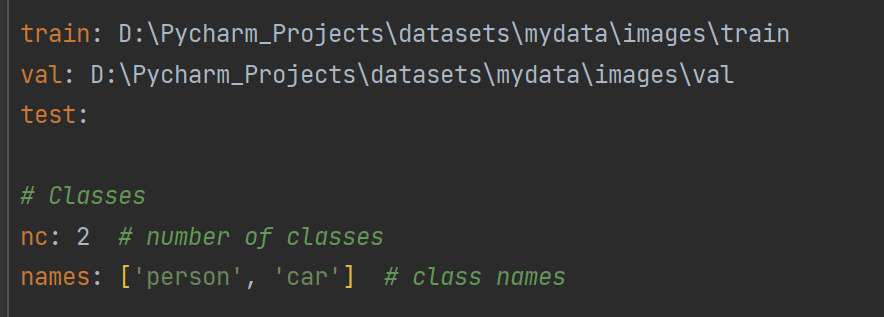
这里主要注意的就是标号代表的意思,比如一些不好的数据集并不会告诉你0代表人,1代表车,2代表狗
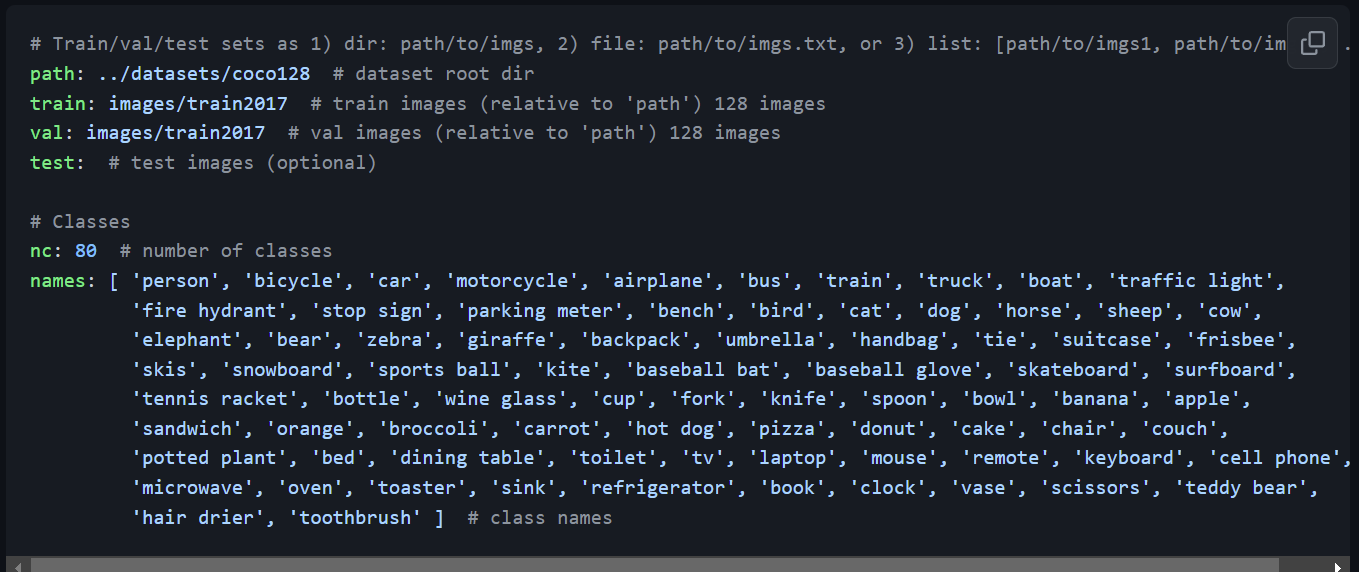
这是官方提供的 data/coco128.yaml,他这里的书写方式和我给出的不同,两种都可以的
3 第三步;修改train.py参数
确认好数据集格式并且写好配置文件后,要改动最后一处:
将这里改成刚才写好的配置文件的路径,然后就可以训练啦👍

4 小知识💡:标签内容解释
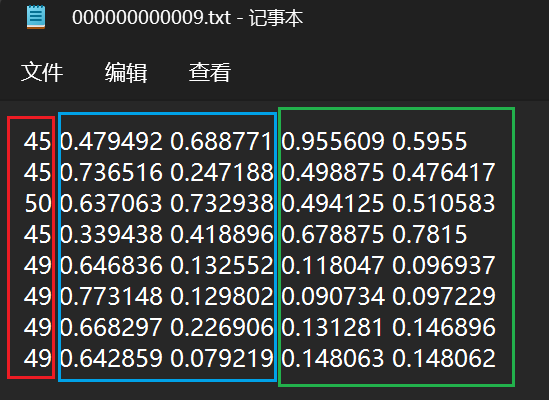
三个部分分别代表:类别;框中心点x坐标,框中心点y坐标;框宽,框高;
5 常见问题🌟
Q1:windows系统路径中不能出现中文,Linux可以出现
Q2:出现“页面太小,无法完成操作”
可能是虚拟内存不足,调大虚拟内存
Wiin系统可以尝试将线程 --workers设为0
Q3:memory error
内存超了,减小 --batch-size
本人更多YOLOv5实战内容导航🍀🌟🚀
-
手把手带你调参Yolo v5 (v6.2)(推理)🌟强烈推荐
-
手把手带你调参Yolo v5 (v6.2)(训练)🚀
-
手把手带你调参Yolo v5 (v6.2)(验证)
-
如何快速使用自己的数据集训练Yolov5模型
-
手把手带你Yolov5 (v6.2)添加注意力机制(一)(并附上30多种顶会Attention原理图)🌟强烈推荐
-
手把手带你Yolov5 (v6.2)添加注意力机制(二)(在C3模块中加入注意力机制)
-
Yolov5如何更换激活函数?
-
Yolov5如何更换BiFPN?
-
Yolov5 (v6.2)数据增强方式解析
-
Yolov5更换上采样方式( 最近邻 / 双线性 / 双立方 / 三线性 / 转置卷积)
-
Yolov5如何更换EIOU / alpha IOU / SIoU?
-
Yolov5更换主干网络之《旷视轻量化卷积神经网络ShuffleNetv2》🍀
-
YOLOv5应用轻量级通用上采样算子CARAFE
-
空间金字塔池化改进 SPP / SPPF / SimSPPF / ASPP / RFB / SPPCSPC / SPPFCSPC🚀
-
用于低分辨率图像和小物体的模块SPD-Conv🍀
-
GSConv+Slim-neck 减轻模型的复杂度同时提升精度🍀
有问题欢迎大家指正,如果感觉有帮助的话请点赞支持下👍📖🌟

 微信公众号
微信公众号
